多节点高性能计算集群设计问题

根据该服务器配置,设计一套多节点的高性能计算集群,要求该集群的总功率不超过3000瓦.画出集群的架构图并说明设计思路和每部分的功能同时列出集群的硬件配置信息和软件信息(包括并行计算环境),并解释这些软件的作用。举例说明采取哪些优化配置可以让这套集群计算性能更好。
请问这个怎么做呀?(ฅ•﹏•ฅ)
设计一套多节点的高性能计算集群需要考虑许多因素,包括集群的硬件配置、软件环境、网络架构和管理系统等。
1.集群架构图,在这种架构中,集群由一个“头节点”和多个“计算节点”组成。头节点用于管理集群,包括提交任务、监控任务状态、分配资源等。计算节点用于执行任务,每个计算节点内部可以有多个 CPU 核心,用于并行计算。
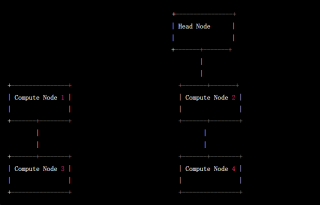
2.集群硬件配置,为了达到高性能,可以考虑使用如下的硬件配置
头节点:
CPU:2 核心 3.0 GHz 或更快的 CPU
内存:8 GB 或更多
硬盘:500 GB 或更大的硬盘
网卡:1 张 1 Gbps 的网卡,用于与计算节点通信
计算节点:
CPU:4 核心 3.0 GHz 或更快的 CPU
内存:16 GB 或更多
硬盘:500 GB 或更大的硬盘
网卡:1 张 1 Gbps 的网卡,用于与头节点通信
3.集群软件配置
为了让集群能够顺利运行,还需要安装一些软件包括:
操作系统:可以选择 Linux 系统,如 Ubuntu、Red Hat Enterprise Linux 等。
网络管理工具:可以使用 Open MPI 或其他工具来管理集群网络。
并行计算环境:可以使用 MPI、OpenMP 或其他工具来实现并行计算。
任务管理工具:可以使用 Slurm、PBS 等工具来管理任务的提交和执行。
其他软件:根据具体的计算需求,还可能需要安装编译器、调试工具、库函数等。
4.优化配置
- 选择合适的 CPU 和内存配置:对于大多数计算任务来说,CPU 和内存是关键的资源。可以选择具有更多核心、更快时钟频率的 CPU,以及更多内存,来提升计算性能。
- 充分利用并行计算工具:可以使用 MPI、OpenMP 等工具,来实现计算节点之间的数据交换和任务分发,从而充分利用集群的资源。
- 使用高速网络:集群内部的网络是计算性能的关键因素之一。可以使用较高带宽的网络,如 10 Gbps 的网络,来提升网络性能。
- 调整任务调度策略:可以使用合适的任务调度策略,如最短作业优先(SJF)、加权最短作业优先(WJSJF)等,来提升任务执行效率。
- 调整编译器优化级别:可以使用编译器的优化功能,来提升代码的执行效率。例如,可以使用 -O3 优化级别,来对代码进行更多的优化。
集群架构图,在这种架构中,集群由一个“头节点”和多个“计算节点”组成。头节点用于管理集群,包括提交任务、监控任务状态、分配资源等。计算节点用于执行任务,每个计算节点内部可以有多个 CPU 核心,用于并行计算。
一个节点类似于一个cpu,这个cpu较好,会有48核数到64核
我们有四台服务器主机,一台login主机。------------共5台主机,也就是5个节点,其中4个节点通过slurm软件进行管理维护。
集群操作系统linux centos7
网络管理工具使用的ib网络,最快的网络传输。
并行计算intelmpi,openmpi
任务管理工具slurm
其他软件高性能库hdf5,petsc,fftw等相关库软件



3、配置节点信息存储系统
安装NFS、PVFS、Lustre 、Luster、GPFS、SNFS等,一般大型的HPC集群用Lustre能获得更好的性能,但不太适合小集群,小集群可以考虑用NFS和PVFS,但NFS并不是面向并行计算的,推荐用PVFS好一点。
关于Lustre:
一个Lustre文件系统主要包括以下四个组件:管理服务器Management Server(mgs), 元数据服务器Meta Data Target(mdt), 对象存储服务器Object Storge Target(ost) ,客户端Lustre clients(lc)。
它主要包括三个部分:元数据服务器MDS (Metadata Server)、对象存储服务器OSS (Object Storage Server)和客户端Client。
正常的启动顺序是:OST -> MDS -> CLIENT
甲骨文产品管理负责人Bob Thome表示:“云文件系统并不是甲骨文首个基于集群文件系统的产品。甲骨文管理着Lustre项目,Lustre更适合于拥有上千台服务器的大规模HPC(高性能计算)部署。云文件系统则更适合于25个节点数左右的小规模部署,尽管Lustre已经通过了多达100个节点的测试。Lustre也可以实现很多相同的功能,但使用门槛较高,安装和配置较为繁琐,并不适合于小规模部署。”
个人建议先用nfs在用lustre.我们用的nfs
关于Lustre的博文:http://www.cnblogs.com/jpa2/category/384788.html
PVFS存在以下不足:
1)单一管理节点。上面说到过PVFS中只有一个管理节点来管理元数据,当集群系统达到一定的规模之后,管理节点将可能出现过度繁忙的情况,这时管理节点将成为系统瓶颈。
2)对数据的存储缺乏容错机制。当某一I/O节点无法工作时,上面的数据将出现不可用的情况。
3)静态配置。对PVFS的配置只能在启动前进行,一旦系统运行则不可再更改原先的配置。
4、集群管理工具(考虑是否集成了一些组件)
集群管理工具 (CMT),它的职能是管理集群。它有多个功能,有的是可选功能。而必须具备的功能包括:
维护计算节点清单(即集群中包括的节点)。只需通过简单如 /etc/hosts 的,就能复制或通过本地 DNS 发送至每个计算节点
创建、管理映像或安装在计算节点上的数据包集
发送映像或数据包到计算节点(一般通过 PXE )
执行对计算节点的基本监控(例如,节点工作情况?什么节点发生起落?)
计算节点电源控制(不是硬性要求,但是强烈推荐)。即远程开启/关闭节点,此功能可以通过各种方法实现,有的方法需要使用增加其他硬件。
虽然这个功能清单对于有集群经验的人来说显得太简短,但清单所载功能是 CMT真正的核心。具备其他功能也不错,但对集群来说并不是必不可少的。
CMT 包括 Platform OCS、Clustercorp ROCKS+、Microsoft Windows CCS 和平台管理器 (Platform Manager) 、Mon等。
5、可选组件:
集群所需的工具并不多,但有了这些就能实现集群的基本运行。不过,它只能满足 1 个用户或 2 至 3 个用户的需要,此外,要实现全面控制和掌握集群的运行情况。要安装一些可选组件,从技术上虽然是可选项,但是没有这些工具,集群就不具备生产能力。
有一些组件可以添加到 CMT 或 CMI 上层。一个有数年管理多个集群经验的人说的,强烈建议您郑重考虑使用以下附加组件:
更加广泛的监控工具,包括集群状态图形视图,例如Ganglia(链接- http://ganglia.info/%EF%BC%89%E3%80%81Cacti%EF%BC%88%E9%93%BE%E6%8E%A5 - http://www.cacti.net/%EF%BC%89%E5%92%8C Nagios(链接 -http://www.nagios.org/)
报告工具,允许您创建关于集群运行情况的报告
用户帐户管理工具(允许您在整个集群上创建用户帐号、允许用户设置密码,然后将其传播到集群的所有节点上,允许无密码登录节点,这对于运行 MPI 应用程序是必需的)
另一个理论上可选,但值得强烈推荐的组件——任务调度器(也被称为资源管理器)任务调度器是一个允许用户提交执行任务、但不参与任务运行的排队系统。任务调度器把提交的任务排成队列,等到资源(即节点)可用时,就开始运行。任务调度器包括:Platform LSF、PBS-Pro 和 MOAB 等。
直接用任务调度器管理
http://www.ibm.com/developerworks/cn/linux/l-cluster1/
http://zh.community.dell.com/techcenter/w/techcenter_wiki/50
http://www.hpcblog.com.cn/
可以看看
http://www.linkzol.com/index.ASP
- 这篇文章:高性能运算集群使用 也许能够解决你的问题,你可以看下