关于#神经网络#的问题:自己猜测是因为模型太复杂过拟合了,怎么解决weka过拟合
使用weka在进行bp神经网络模型建立后,训练集效果良好,但是验证集效果很差。
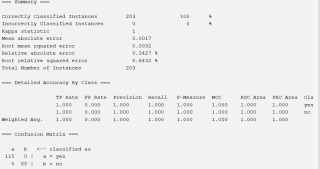
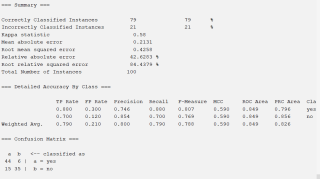
自己猜测是因为模型太复杂过拟合了,怎么解决weka过拟合
一种解决过拟合的方法是使用正则化。正则化通过限制模型的复杂度来减少过拟合的风险。在weka中,可以使用训练算法的“-R”参数来设置正则化系数。例如,使用命令“java weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a -R 1.0e-3 -D”可以设置神经网络的正则化系数为1.0e-3。
另一种解决过拟合的方法是使用交叉验证。交叉验证通过将数据集分成训练集和测试集,并在训练集上训练模型,在测试集上测试模型的性能,来减少过拟合的风险。在weka中,可以使用“-x”参数来设置交叉验证的折数。例如,使用命令“java weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a -x 10”可以设置交叉验证的折数为10。
望采纳!!点击该回答右侧的“采纳”按钮即可采纳!!
我说说我的想法吧——面对过拟合
**
1.减少网络的层数和神经元数量:过多的层数和神经元可能会使模型变得复杂,导致过拟合。
2.增加训练数据量:增加训练数据量可以使模型更好地拟合数据,减少过拟合的风险。
3.使用正则化:正则化是指在损失函数中加入一个惩罚项,以防止模型的过度拟合。在 weka 中,你可以在设置神经网络模型时选择正则化方法。
4.提高学习率:通常来说,当学习率较小时,模型的收敛速度会变慢,导致训练时间较长。但是,如果学习率过大,模型可能会在训练过程中经历多次抖动,导致过拟合。
(私人丹方——学习率最好是从高到底2倍速度递减一般从0.01开始)
5.使用批量标准化:批量标准化是指将每一层的输入数据进行标准化处理,使得每一层的输入数据都具有相同的分布。这可以有效减少模型过拟合的风险。
6.使用提前停止:提前停止是指在训练过程中,通过监测验证集的表现来决定是否停止训练。如果验证集的表现没有提升,则停止训练,以防止过拟合。
7.使用更简单的模型:使用简单的模型可以减少过拟合的风险。例如,在 bp 神经网络模型中,可以使用更少的层数和神经元,或者使用其他类型的模型,如线性回归或决策树。
**
不能因为尝试了很多机器学习方法,就期望在新的数据集上取得相同效果,尝试很多,最终选择可能过拟合。使用交叉验证,得到的结果也不够,在这种情况下,把数据分为训练数据、测试数据和验证数据,使用训练和测试数据来选择机器学习方法,选择最适合训练的和测试的,或者使用交叉验证选择最适合训练数据的。选择好机器学习方法后,再使用验证数据来评估他针对的测试数据的真实效果。
请采纳哦。望你的问题早日解决!!
可以先删除outlook属性,然后在OneR设置分类时把minBucketSize改为10或者更大,这个值一般默认是6,数值越大,对过拟合的抑制性越强
如果问题解决的话请点 采纳~
1.问题初步定位:可能是因为模型过拟合了训练数据。
2.概念描述:过拟合是指模型在训练数据上的表现很好,但是在新数据(例如验证集或测试集)上的表现很差。这通常是因为模型过于复杂,导致模型学习了训练数据中的噪声和特异性,而没有学习数据的一般规律。
3.解决过拟合问题,可以尝试以下方法:
①.增加数据量:如果你的训练数据量很少,可能会导致模型过拟合。尝试增加数据量,看看是否能改善模型的表现。
②.减少模型复杂度:如果你的模型过于复杂,可能会导致过拟合。你可以尝试减少模型的复杂度,例如减少神经网络的层数或者神经元的数量。
③.使用正则化:正则化是一种技术,可以限制模型的复杂度,从而减少过拟合的风险。你可以在 weka 中使用正则化来解决过拟合问题。
④.使用交叉验证:交叉验证是一种评估模型泛化能力的方法,它通过将训练数据分成若干份,然后分别用每一份数据做一次验证,最后将验证结果取平均值来得出最终的评估结果。
WEKA( OneR,过拟合)
借鉴下
https://blog.csdn.net/dujuancao11/article/details/114295997
有几个方法可以尝试来降低过拟合:
1、增加数据量。这是最常见的方法,因为更多的数据可以帮助模型学习更多的真实规律而不是训练集中的噪声和随机偏差。
2、减少模型复杂度。这包括减少模型中的参数数量(例如减少神经网络的隐藏层数量或者减少每层的节点数量)或者使用正则化(例如 L1 正则化或 L2 正则化)来限制模型的复杂度。
3、增加正则化系数。如果已经使用正则化,但是过拟合仍然存在,可以尝试增加正则化系数以进一步限制模型的复杂度。
4、使用 dropout。Dropout 是一种常用的正则化方法,它会随机将神经网络的节点设置为 0,从而防止模型过拟合。
5、使用数据增强。数据增强是通过对训练集中的图像进行一些变换来生成新的训练数据的方法。这可以让模型学习到更多的规律,并且降低对训练集中的噪声和随机偏差的依赖。
6、使用早期停止。早期停止是指在训练过程中,当验证集上的性能不再提升时停止训练。这可以帮助防止模型过拟合训练数据。
7、使用 bagging 或 boosting 等集成学习方法。这些方法可以通过训练一组弱学习器(例如决策树)然后将它们组合起来,从而得到一个强大的学习器。这些方法可以降低对单个学习器的过拟合的依赖,从而提升泛化能力。
在使用 weka 进行 bp 神经网络模型建立后,训练集效果良好,但是验证集效果很差,可能是因为模型出现了过拟合的情况。
过拟合是指模型在训练集上表现良好,但是在验证集或新数据上表现不佳的情况。过拟合通常是由于模型过于复杂或者训练数据不足导致的。要解决 weka 中 bp 神经网络模型的过拟合问题,可以尝试以下方法:
- 增加训练数据:增加训练数据可以帮助模型更好地拟合数据,减少过拟合的可能性。
- 减少模型复杂度:减少模型的复杂度。
- 使用正则化:正则化是一种常见的用于减少模型过拟合的方法。正则化通过在损失函数中加入一项惩罚项,使模型参数变小,从而减少模型的复杂度。weka 中 bp 神经网络模型可以通过调整 "hiddenLayers" 参数来设置正则化,具体方法是:在 "hiddenLayers" 参数后面加上一个数字,表示惩罚系数。例如,"hiddenLayers=5 1" 表示使用惩罚系数为 1 的正则化。
- 使用早停法:早停法是一种在训练过程中提前停止训练的方法,用于避免模型过拟合。weka 中 bp 神经网络模型可以通过调整 "validationThreshold" 参数来设置早停法,具体方法是:将 "validationThreshold" 设置为一个较小的值,表示在验证误差较大时停止训练。例如,"validationThreshold=0.01" 表示在验证误差大于 0.01 时停止训练。