python读取txt无法识别’\n‘
如题,本人在进行命名实体识别时需要处理txt文本数据,由于该数据中存在'\n'换行符,因此需要加一个判断来处理,但python程序似乎无法识别'\n',写的判断语句并没有将txt中的'\n'识别出来。以下是部分代码:
python程序:
with open("train1.txt", 'r', encoding='utf-8') as f:
word_list = []
tag_list = []
i=1
for line in f:
print(line,i)
i+=1
if line != '\n':
word, tag = line.strip('\n').split()
word_list.append(word)
tag_list.append(tag)
else:
print(word_list)
word_lists.append(word_list)
tag_lists.append(tag_list)
word_list = []
tag_list = []
txt数据预览:
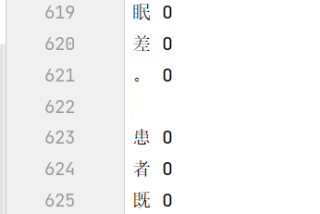
报错信息:
ValueError: not enough values to unpack (expected 2, got 0)
检查文件格式,如果是Windows上的文件格式,空白行是if line != '\r\n',如果是Linux则是\n。
修改后的代码为
with open("train1.txt", 'r', encoding='utf-8') as f:
word_list = []
tag_list = []
for line in f:
if len(line.strip().replace(" ", ""))>=2:
word, tag = line.strip().split()
word_list.append(word)
tag_list.append(tag)
else:
word_lists.append(word_list)
tag_lists.append(tag_list)
word_list = []
tag_list = []
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7650965
- 这篇博客你也可以参考下:关于python无法读取txt文件的另一种解决方式......
- 这篇博客也不错, 你可以看下关于python无法读取txt文件的另一种解决方式......