Java Socket 传输数据量大时接收端与发送端数据不一致问题
Java Socket传输字节流时接收端与发送端数据不一致问题
我做的一个TCP传输方法,每次在传输数据时在包头打上数据包大小,在接收端接收到足够大小后再进行处理,在传输数据量小的时候不会出错,但一旦数据量大到几十K时也就是字节数量达到30000时,接收端出现了接受端和发送端发送的字节数量都不一致了,接收端的字节数量时不时会大于发送端,有时多出来几百个字节,有时候多出来几千个字节,更麻烦的是我不知道多出来的字节在哪里,他们插在了这些数据包中间,我在查看发送端和接收端的字节流不同时发现发送端最后几个字节和接收端最后几个字节一致,但接收到的字节数量不一致,我以为是不是发送端在发送时变成了多线程,我尝试调试,可我把断点设置到接收端的InputStream.read时这种现象又离奇的消失了,于是我尝试着在read之前sleep几毫秒,问题也没有出现,但明显这种方法治标不治本且鸡肋,在此
运行结果及详细报错内容
这是发送端运行:
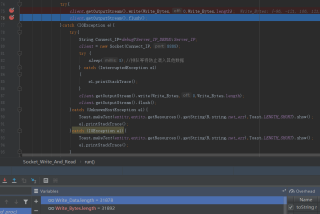
最下方是我这个write的数组的大小
可是在接收端:
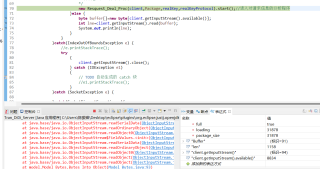
右下角监视的client.getInputStream().available()还有8834,说明缓冲区内还有8834个,可是我已经把发送端发送的数据大小全部读取了,而且读的还是有错误的
可是如果我在前面的

read部分加上断点时它就不会有这种情况了
我的解答思路和尝试过的方法,我发现设置断点时它就不会产生这种情况的话,我就在read前面加上sleep也没有产生这种情况,但这种方法很鸡肋,浪费服务器资源不说,如果不同的网络情况我还得调整这个sleep,我猜测产生这个现象的原因是由于发送的write时byte[]数组过大导致发生拆包,但后面的包到达后马上就被read了(可是TCP协议不应该是保证读取有序吗),导致中间空出的字节被覆盖了,后面到达的包就只能排到后面了,可是我没有办法判断我在接受端write的byte[]数组资源全部到达接收端啊。希望能有解我疑惑
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
可以看下该实例中对于Java Socket 数据传输 基础以及优化,链接:https://blog.csdn.net/z1766042975/article/details/112709438
就是如果我在发送端发送后在接收端的read之前停住等个一会儿(sleep几毫秒也可以)就不会产生接收端和发送端不一致情况,要是不等的话接收端的字节流长度就大于发送端了,而且还不是单纯加在发送端字节流后面,而是插在了中间,猜测是TCP拆包时,后部的包先到而且还被读了,前面的就默认读了0字节,导致后面到达的包加在了后面,但我学的TCP知识告诉我前面的包没到应该读不到后面的包啊,还有没有可能是接收端和发送端同时在读写导致的字节流重复了?
代码写的不对,可能错误位置:
while(!Package){
len= xxxx
//这里对收到的长度没有判断
}
一个是让server每交发送时间间隔大点。第二个就是在client端采用socket的异步接收处理。
个人推荐使用第二种方法,msdn中在socket里有相关的异步处理说明和例子,你可以看看
你这显然就是网络开发中常会遇到的问题,大数据包的分包、拆包、黏包问题。
1、大数据包会被发送端切割成多个ip包有序的调用网卡发送,但不意味着这些数据包在到达接收端时也是有序的!(这些数据包如果经过互联网传输就会遇到丢失、网络拥塞等问题)
2、你这里在read方法钱调用sleep主动等待后就没有问题,因为操作系统会主动帮你把这些ip包分片组合起来给你,但在bio模型中read方法只阻塞到第一个ip包分片过来就会醒来,不管后续的ip包分片有没有来全,所以你主动sleep后可以保证这些ip包分片全部接收全,然后read自然就是全的数据。
3、接收端代码问题,如果是用bio读取本地文件,那可以用available(),如果是网络io的数据读取,就绝不用available()方法。
ByteBuffer buff = ByteBuffer.allocate(10240);
byte[] temp = new byte[1024];
int len = 0;
while ((len = io.read(temp)) > 0) {
buff.put(temp, 0, len);
}
byte[] data = buff.array();