想要将公交GPS数据与线网数据分别匹配报错Columns must be same length as key
想要将公交GPS数据与线网数据分别匹配报错Columns must be same length as key
代码如下:
tmp_list = list()
for i in range(1,11):
# 取出第i条线路的数据
tmp = BUS_GPS_2416[BUS_GPS_2416['new_id'] == i]
# 提取第i条线路
lineshp = line_2416[line_2416['line_name'] == tmp['Linename'].iloc[0]]
tmp['project'] = tmp['new_id']
# 利用project方法,将数据点投影至公交线路上
tmp['project'] = tmp['geometry'].apply(lambda r:lineshp.project(r))
# 原始的数据点存储在一个字段内
tmp['geometry_orgin'] = tmp['geometry']
# 利用interpolate方法,生成匹配的坐标点
tmp['geometry'] = tmp['project'].apply(lambda r:lineshp.interpolate(r))
# 计算原始点和匹配点之间的距离
tmp['diff'] = tmp.apply(lambda r:r['geometry_orgin'].distance(r['geometry']),axis = 1)
tmp_list.append(tmp)
BUS_GPS_clean = pd.concat(tmp_list, axis=0, ignore_index=False)
BUS_GPS_clean
报错:
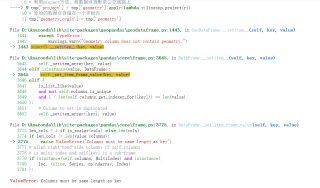
拼接数据时,你会发现报错信息中有一句话是这样的:"Columns must be same length as key"。这意味着在拼接数据时,拼接的数据的列数不一致。
为了解决这个问题,你需要检查一下在循环中每次生成的tmp数据中有没有缺失的列,或者有没有多余的列。
你可以在循环的每一次迭代中,使用df.info()函数来查看数据的信息,看看是否有缺失的列或者多余的列。
如果你发现某一次迭代中的tmp数据中有缺失的列或者多余的列,你需要调整你的代码,使得每一次迭代中生成的tmp数据的列数都是一致的。
此外,你也可以使用df.columns来查看数据的列名,以确保每一次迭代中生成的tmp数据的列名都是一致的。