python 分隔符问题
CODE2中的内容是由一段编码+“|“+中文名称,但是其中可能有很多编码及其所属的中文,并被逗号分开,像第4行那样。现在想把CODE2中的所有编码保留下来,并分别变成名字1,2,3,4,5等等,编码的中文意义删掉。
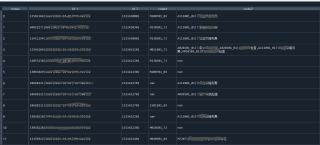
我的思路:先把”逗号和“|”分号拆掉,并且自动分列,再把其中的中文意义列再drop掉
刚开始用split,但是split函数只能删除一个分隔符。之后使用rsplit函数,但是用了之后发现rsplit 不管怎么,都无法成功一下分解2个分隔符。
代码如下
c=a['code2'].str.rsplit('[,|]',expand=True)
运行结果及详细报错
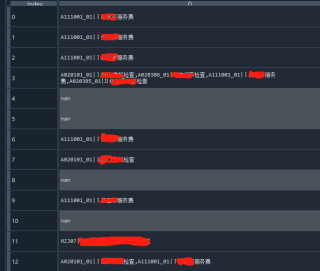
我尝试了一下,需要好几个步骤
a=a['code2'].str.rsplit(',',expand=True)
c=a['code2'].rsplit('[,|]',expand=True)
b=a['code2'].str.split(',',expand=True)
b1=b[0].str.split('|',expand=True)
但是问题是如果这样做的话,原本与其相匹配的id_1和id_2就不见了,而起一起只能处理其中其中一列,如果有10列,过程过于繁琐。有没有简单的办法,又能直接从原来的表直接自动生成相关列?
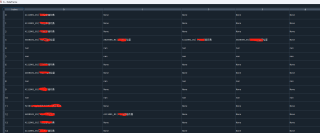
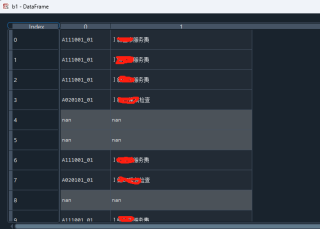
建议使用re.split 分隔符,或者你split两次也可以啊,先split | 然后在逗号
你先引用re,
re.split函数允许输入多个分隔符,你把逗号和|都作为分隔符去分割,这样偶数位置是你要的,奇数位置是要丢掉的,不用循环drop,写个切片
a[::2]就行了
描述太乱, 建议直接给出几条测试数据和要达成的最终效果, 你的已写的代码粘贴出来即可, 无需过多描述
import re
data = 'test,|test,|'
data = re.split(r'([\|,])', data)
print(data)
如果编码的长度是固定的,根据 | 分割后,截取后几位就可以了
参照这个实例介绍【【Python】分割字符串 空格、逗号,分号;】,链接:https://blog.csdn.net/YaoYee_21/article/details/119743685
import pandas as pd
def split_data(df):
l_len = len(df.columns)
res = df['code2'].str.split(',')
l_max = len(max(res, key = lambda x: len(x)))
for i in range(l_max):
t = [res[j][i].split('|')[0] if len(res[j]) > i else '' for j in range(len(res))]
df.insert(loc = l_len+i, column = i, value = t)
del df['code2']
data = [['1258', 'A111001_01|xx,A43|yy'], ['9485', 'A111001_01|bb,B123|cc'], ['1141', 'A0200101_01|aa,A020306|gggg,A11101_01|uuuu']]
df = pd.DataFrame(data, columns=['id1', 'code2'])
split_data(df)
print(df)
--result
id1 0 1 2
0 1258 A111001_01 A43
1 9485 A111001_01 B123
2 1141 A0200101_01 A020306 A11101_01
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632