python代码简化,dataframe应用
问题遇到的现象和发生背景
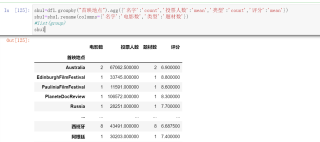
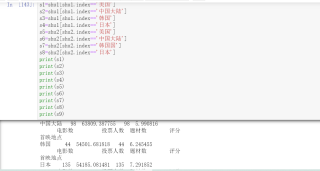
s1=shu1[shu1.index=='美国']
s2=shu1[shu1.index=='中国大陆']
s3=shu1[shu1.index=='韩国']
s4=shu1[shu1.index=='日本']
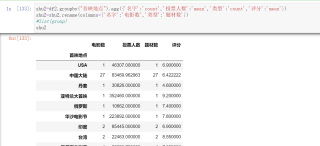
s5=shu2[shu2.index=='美国']
s6=shu2[shu2.index=='中国大陆']
s7=shu2[shu2.index=='韩国国']
s8=shu2[shu2.index=='日本']
print(s1)
print(s2)
print(s3)
print(s4)
print(s5)
print(s6)
print(s7)
print(s8)
print(s9)
我想要达到的结果
想要润色一下这段代码,应用dataframe,希望简便好看一些
测试可以把注释的打开,试试。
l = ['美国','中国大陆','韩国', '日本','美国','中国大陆','韩国国','日本',]
n = 0
for li in l:
if n < 4:
print(shu1[shu1.index == f'{li}'])
# print(f"shu1[shu1.index=='{li}']'")
else:
print(shu2[shu2.index==f'{li}'])
# print(f"shu2[shu2.index=='{li}']")
n += 1