存在一定规律的数据转置和整理
纯excel不高级使用者,因近期需要批量收集信息,用爬虫爬下来了一堆数据,但格式不太理想,为了让后续数据能被用于数据分析,需要进行转置和规范化,希望不吝赐教数据清洗的我
我的解答思路和尝试过的方法:用excel 手动进行转置
我想要达到的结果:通过python 或excel (Power BI) 或tableau 自动化地完成转置,大概有几千个相同格式的数据需要处理,实在无法手动进行。
第一行第一列(即图中的“抚州市”不动)
下面四行:
首先 “转置”( 如图excel ) 到第一行的后面
然后,需要手工删掉
下面的数据,每五行的操作跟之前一样,
详情请看图片和附表:

| 所属省(市) | 所属税务机关名称 | 失信主体名称 | 纳税人识别号 | 主体违法性质 |
|---|---|---|---|---|
| 抚州市 | 资溪县续申药业有限公司 | 91361028MA361AC20 | 康水平 | 虚开增值税专用发票或者虚开用于骗取出口退税、抵扣税款的其他发票 |
| 资溪县续申药业有限公司 | ||||
| 91361028MA361AC20 | ||||
| 康水平 | ||||
| 虚开增值税专用发票或者虚开用于骗取出口退税、抵扣税款的其他发票 |
解决如下:
import pandas as pd
df = pd.read_excel(r'C:\a.xlsx', header=None)
print('处理之前: \n', df)
result = []
tmp_list = []
for index, row in df.iterrows():
tmp_list.append(row[0])
if index % 5 == 4:
result.append(tmp_list)
tmp_list = []
df = pd.DataFrame(result, columns=['所属省(市)', '所属税务机关名称', '失信主体名称', '纳税人识别号', '主体违法性质'])
print('处理之后: \n', df)
df.to_excel(r'C:\result.xlsx', index=False)
数据处理之前:
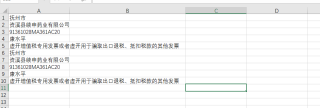
数据转置处理之后:

假设你的数据都在excel 的"数据"列
import pandas as pd
import numpy as np
df1=pd.read_excel('D:/ZZF/data.xlsx')
lt=list(df1['数据'])
m=5-len(lt)%5
m1=[lt.append('') for i in range(m)]
cols=['所属省(市)','所属税务机关名称','失信主体名称','纳税人识别号','主体违法性质']
df2=pd.DataFrame(np.array(lt).reshape(-1,5),columns=cols)
print(df2)