ID3决策树实现分类
要求:随机生成声音数据在excel(非整数),范围在15-60,5000个数据。根据数据来判断人在睡觉时的动静情况做出相应的判断。分贝小则是睡得好反之睡不好。因为不懂算法,希望能写出此算法,并声称决策图。matlab或python都可以,附带解释。
其实比起决策树,我觉得你更需要数据集合,我有睡眠数据集合
信息增益
ID3算法使用的数据特征函数(标准)为信息增益。
首先,我们介绍一下熵的概念,熵表示的是不确定度,熵越大,不确定度就越大。假设在数据D中有k kk个类别,其中第i ii个类别数据在总数据中占有率为p i p_ip
i
,则熵的计算公式为:
i n f o ( D ) = − ∑ i = 1 k p i l o g 2 ( p i ) info(D) = - \sum_{i=1}^{k}p_ilog_2(p_i)
info(D)=−
i=1
∑
k
p
i
log
2
(p
i
)
当我们使用某一特征A对数据分类后,其不确定度会减小(因为数据数据有所划分)。此时的熵也会减小,假设特征A有m个类别,其计算公式为:
i n f o A ( D ) = − ∑ j = 1 m ∣ D j ∣ ∣ D ∣ × i n f o ( D j ) info_A(D) = - \sum_{j=1}^{m}\dfrac{|D_j|}{|D|}×info(D_j)
info
A
(D)=−
j=1
∑
m
∣D∣
∣D
j
∣
×info(D
j
)
那么分类前后熵减小的差值就是信息增益。
G a i n ( A ) = i n f o ( D ) − i n f o A ( D ) Gain(A) = info(D) - info_A(D)
Gain(A)=info(D)−info
A
(D)
我们一一计算所有变量的信息增益,选择信息增益最大的那个变量作为此分类节点。
数据简介
为了详细介绍如何用ID3算法生成一颗树,我们设定一组贷款数据如下:
我们将通过年龄、是否有工作、是否有房子和信贷情况四个自变量来区分贷款的审批结果。
计算过程
第一层
总体信息熵:
i n f o ( D ) = − 9 15 l o g 2 ( 9 15 ) − 6 15 l o g 2 ( 6 15 ) = 0.9710 info(D) = -\dfrac{9}{15}log_2(\dfrac{9}{15})-\dfrac{6}{15}log_2(\dfrac{6}{15}) = 0.9710
info(D)=−
15
9
log
2
(
15
9
)−
15
6
log
2
(
15
6
)=0.9710
计算年龄A1的信息熵:
i n f o ( D ∣ A 1 = 老 年 ) = − 4 5 l o g 2 ( 4 5 ) − 1 5 l o g 2 ( 1 5 ) = 0.7219 info(D|A1 = 老年) = -\dfrac{4}{5}log_2(\dfrac{4}{5})-\dfrac{1}{5}log_2(\dfrac{1}{5}) = 0.7219
info(D∣A1=老年)=−
5
4
log
2
(
5
4
)−
5
1
log
2
(
5
1
)=0.7219
i n f o ( D ∣ A 1 = 中 年 ) = − 3 5 l o g 2 ( 3 5 ) − 2 5 l o g 2 ( 2 5 ) = 0.9710 info(D|A1 = 中年) = -\dfrac{3}{5}log_2(\dfrac{3}{5})-\dfrac{2}{5}log_2(\dfrac{2}{5}) = 0.9710
info(D∣A1=中年)=−
5
3
log
2
(
5
3
)−
5
2
log
2
(
5
2
)=0.9710
i n f o ( D ∣ A 1 = 青 年 ) = − 2 5 l o g 2 ( 2 5 ) − 3 5 l o g 2 ( 3 5 ) = 0.9710 info(D|A1 = 青年) = -\dfrac{2}{5}log_2(\dfrac{2}{5})-\dfrac{3}{5}log_2(\dfrac{3}{5}) = 0.9710
info(D∣A1=青年)=−
5
2
log
2
(
5
2
)−
5
3
log
2
(
5
3
)=0.9710
i n f o ( D ∣ A 1 ) = 1 3 × 0.7219 + 1 3 × 0.9710 + 1 3 × 0.9710 = 0.8880 info(D|A1) = \dfrac{1}{3}×0.7219+\dfrac{1}{3}×0.9710+\dfrac{1}{3}×0.9710=0.8880
info(D∣A1)=
3
1
×0.7219+
3
1
×0.9710+
3
1
×0.9710=0.8880
则A1的信息增益为:
G a i n ( A 1 ) = 0.9710 − 0.8880 = 0.083 Gain(A1)=0.9710 - 0.8880 = 0.083
Gain(A1)=0.9710−0.8880=0.083
按照此方法,
G a i n ( A 2 ) = 0.324 Gain(A2) = 0.324Gain(A2)=0.324 ;
G a i n ( A 3 ) = 0.420 Gain(A3) = 0.420Gain(A3)=0.420 ;
G a i n ( A 4 ) = 0.363 Gain(A4) = 0.363Gain(A4)=0.363
由此可见,我们将使用变量A3:是否有房子来作为第一分类特征。
第二层
A3 = “是"时数据如下:
发现他们的贷款审批结果都是"是”,其熵等于0,可以作为叶节点。
A3 = "否"时数据如下:
此时的总体信息熵:i n f o ( D A 3 ) = 0.9183 info(DA3) = 0.9183info(DA3)=0.9183
G a i n ( A 1 ) = 0.2516 Gain(A1) = 0.2516Gain(A1)=0.2516 ;
G a i n ( A 2 ) = 0.9183 Gain(A2) = 0.9183Gain(A2)=0.9183 ;
至此不需要在计算G a i n ( A 4 ) Gain(A4)Gain(A4)了,因为A2已经将数据完全划分开了。
在本数据集中,A1和A4对于数据的划分没有作用。
所得树图:
在树图中,(1/2/8/9/10/14)(3/4/13)(5/6/7/11/12/15)是三个叶节点,代表了三个分类好的子集;其他非叶节点表示的是逻辑判断。
一般而言,我们都需要对树进行剪枝。因为我们划分枝叶的根据是熵增,只要有熵增就需要分枝,这样会很有可能造成过拟合的情况。我们将在下一篇中介绍树的剪枝。
决策树的完整实现:https://blog.csdn.net/gjy_hahaha/article/details/120807804
这里有篇【基于python个人睡眠质量分析设计与实现】实例,期望在你编写程序的过程中,对你有所帮助:https://blog.csdn.net/andrew_extra/article/details/125458084
【虽然可能不是完全和你的需求一致,但文中有提到【本项目利用 pandas + Matplotlib + seaborn + sklearn 等工具包,对睡眠数据进行探索式可视化分析,并构建 KNN、LR、决策树、随机森林等算法实现对睡眠质量的预测建模。】相信应该可以助力你】
数据发来看下,做个网盘链接也可以
你好,你说的决策树算法其实是一种树形结构,每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别,构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好(即信息增益越大越好),这样我们有望得到一棵高度最矮的决策树。ID3作为一种经典的决策树算法,是基于信息熵来选择最佳的测试属性,其选择了当前样本集中具有最大信息增益值的属性作为测试属性。
去aistudio找个例子就能模仿了
#
import pandas as pd
import numpy as np
# 生成数据
noise_data=np.random.randint(15,60,5000)
# # 保存数据
# # openpyxl 依赖 要安装
# pd.DataFrame({"noise_data":noise_data}).to_excel("noise.xlsx",index=False)
# # 读取数据
# noise_data=pd.read_excel("noise.xlsx")
# noise_data=noise_data.values.reshape([-1])
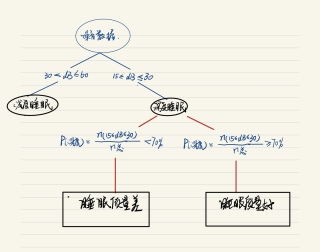
# 浅度睡眠 30< db <=60
sleep=noise_data[(noise_data<=60)&(noise_data>30)].copy()
deep_sleep=noise_data[(noise_data<=30)&(noise_data>=15)].copy()
if deep_sleep.size/noise_data.size>=0.7:
print("睡眠质量好",deep_sleep.size/noise_data.size)
else:
print("睡眠质量差",deep_sleep.size/noise_data.size)
if __name__ == '__main__':
pass
按照要求生成虚拟数据
import numpy as np
all_num=5000#数据总数
sdsm_num=3000#3000人深度睡眠
smzlc_num=1000#3000人深度睡眠中有1000人睡眠质量差
qdsm_data=np.random.randint(30,60,(all_num-sdsm_num))#浅度睡眠数据
qdsm_label=[0]*(all_num-sdsm_num)
smzlc_data=np.random.randint(21,30,smzlc_num)#睡眠质量差数据
smzlc_label=[1]*smzlc_num
smzlh_data=np.random.randint(15,21,sdsm_num-smzlc_num)#睡眠质量好数据
smzlh_label=[2]*(sdsm_num-smzlc_num)
all_data=qdsm_data.tolist()+smzlc_data.tolist()+smzlh_data.tolist()
all_label=qdsm_label+smzlc_label+smzlh_label
#打乱数据排序
from random import shuffle
c = list(zip(all_data,all_label))
shuffle(c)
all_data,all_label = zip(*c)
all_data=np.array(all_data).reshape(-1,1)
2、使用决策树进行判断并可视化决策树
import numpy as np # 使用数组
import matplotlib.pyplot as plt # 可视化
from sklearn.tree import DecisionTreeClassifier # 树算法
from sklearn.tree import plot_tree # 树图
rcParams['figure.figsize'] = (25, 20)
estimator=DecisionTreeClassifier()
estimator.fit(all_data, all_label)
# 4.2评估
print(estimator.score(all_data, all_label))
plot_tree(estimator,
feature_names = ['DB'],
class_names = ['qdsm','smzlh','smzlc'],
filled = True,
rounded = True)
plt.savefig('tree_visualization.png')
决策树可视化

价格牛逼~第一次见