关于#Python#的问题,如何解决?
Python实验
有没有人帮帮我啊,感谢
给定一个成绩单CSV文件Grade.csv,存储格式为:每一行为学号、姓名、科目、该科目对应的成绩,各项以1个逗号分隔。
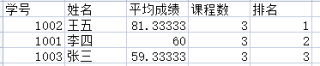
(1)计算每位同学的平均成绩,按照平均成绩降序排名,并写入csv文件(文件名:AvgGrade.csv)中,csv文件的格式为:每一行为学号、姓名、平均成绩、科目数、排名。
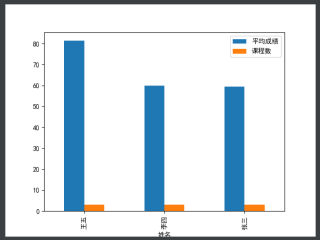
(2)根据平均成绩生成柱状图或饼形图,统计分析出60分以下、60-69分、70-79分、80-89、90分及以上各多少同学等。
- 读CSV文件Grade.csv;
- 读入每一行,分析出该同学每一科的成绩,并选用合适的数据结构存放同学的学号、姓名及成绩;
- 统计出每位同学的平均成绩;
- 按平均成绩排名;
- 写csv文件AvgGrade.csv;
- 生成柱状图或饼形图。
csv文件存储的表格是这样的学号 姓名 课程 成绩 1003 张三 A 60 1003 张三 B 53 1001 李四 B 59 1002 王五 C 97 1002 王五 B 55 1001 李四 A 52 1003 张三 C 65 1002 王五 A 92 1001 李四 C 69
import pandas as pd
import matplotlib.pyplot as plt
if __name__ == '__main__':
df = pd.read_csv("Grade.csv", encoding='gbk')
result = df.groupby(['学号', '姓名'])['成绩'].agg(['mean', 'count']).reset_index()
result.rename({'mean': '平均成绩', 'count': '课程数'}, axis=1, inplace=True)
result.sort_values(by='平均成绩', ascending=False, inplace=True, ignore_index=True)
result['排名'] = result.index + 1
# 导出excel
result.to_csv("AvgGrade.csv", index=False)
# 生成柱状图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
result.plot.bar(x='姓名', y=['平均成绩', '课程数'])
plt.show()
用pandas的read_csv函数读取,然后进行数据处理,最后用matplotlib.pyplot的bar函数绘制柱状图,或者plot()绘制折线图
- 可以查看手册:python-2to3 - 自动将 Python 2 代码转为 Python 3 代码 中的内容
统计各分数段人数

# 60分以下、60-69分、70-79分、80-89、90分及以上各多少同学
# 设置分段
bins=[0,60,70,80,90,101]
# 按分段离散化数据
segments=pd.cut(df['成绩'],bins,right=False)
# # 统计各分段人数
counts=pd.value_counts(segments,sort=False)
# # 绘制柱状图
plt.bar(counts.index.astype(str),counts)
plt.show()