matlab初学者求解答
我现在遇到问题是,我想要提取文件中的第二列和第四列的数据,我如何在命令行窗口把这个文件做成矩阵,并且提取出我想要的数据,而且这是该项目一天的数据,其他364天的文件样本需要同样提取,且共有多个不同的站点,及第一行名称不同,该怎么应用循环函数。
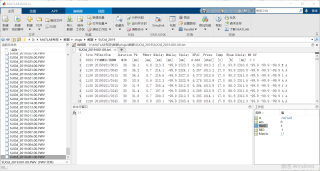
分析你的文件名可以看到文件名的格式为SUOd_2019.0**.00.PWV,只需要写一个循环假设从0到50,就会读到SUOd_2019.000.00.PWV到SUOd_2019.050.00.PWV,用a存下来,利用a(:,2)得到第二列,用a(:,4)得到第四列
不太清楚你文件是怎么命名的,就假设只有中间的数字会变,下面的代码就可以拿到数据了,后面你想把数据存到excel还是做些什么处理就看你自己的需求了。
for i=1:365
filename = ['SUOd_2019.' num2str(i,'%03d') '.00.PWV.txt'];
fileId = fopen(filename);
line=1;
fgetl(fileId);
fgetl(fileId);
while ~feof(fileId)
datat = textscan(fileId,'%s %s %f %f %*[^\n]');
data(line,:) = datat(:,2:2:4);
line = line+1;
end
fclose(fileId);
end