关于#python#的问题:目前是根据‘id’和‘conditions’分好类的dataframe,但是每个id和conditions所对应的cycle列并没有完整的数据(比如cycle=1、2、3
根据dataFrame某一列如何插值生成其他列的所有数据?目前是根据‘id’和‘conditions’分好类的dataframe,但是每个id和conditions所对应的cycle列并没有完整的数据(比如cycle=1、2、3。。的所有对应值)
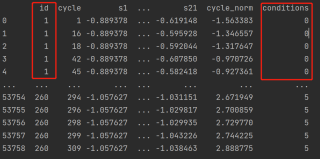
我想要经过插值得到每个id和conditions所对应的cycle列的所有值的数据。
要变成啥样?
你应该是想把同组的cycle都放在一行把,下面写了个demo,你看看应该是你想要的结果
源数据:

结果:

代码:
import pandas as pd
if __name__ == '__main__':
df = pd.DataFrame([
{"id": 1, "cycle": 1, "conditions": 0},
{"id": 1, "cycle": 2, "conditions": 0},
{"id": 1, "cycle": 3, "conditions": 1},
{"id": 1, "cycle": 4, "conditions": 1},
{"id": 2, "cycle": 5, "conditions": 0},
{"id": 2, "cycle": 6, "conditions": 0}
])
dfList = []
for key, item in df.groupby(['id', 'conditions']):
# cycle不是字符串类型需要用apply转一下,如果是字符串类型的话,直接cycleList = item['cycle'].tolist()就行
cycleList = (item['cycle'].apply(lambda x: str(x))).tolist()
dfList.append({"id": key[0], "cycle": ",".join(cycleList), "conditions": key[1]})
result = pd.DataFrame(dfList)
print(result)
