sql server 批量循环更新同一个表里数据
sql server 表里数据如下:
year(年) month(月) productID(产品ID) begamt(月初余额) inamt(本月入库) endamt(月末余额)
2022 11 1 100 20 120
2022 11 2 200 30 230
2022 12 1 0 80 0
2023 2 2 0 60 0
2023 5 2 0 70 0
需要循环更新表里的月初余额、月末余额。更新条件为同样的产品ID,用小于当前年月的最大年月的月末余额作为当前年月的月初余额
更新后的数据应为:
year(年) month(月) productID(产品ID) begamt(月初余额) inamt(本月入库) endamt(月末余额)
2022 11 1 100 20 120
2022 11 2 200 30 230
2022 12 1 120 80 200
2023 2 2 230 60 290
2023 5 2 290 70 360
为了执行速度,需要用一条sql语句更新完成,不能用循环语句,不能用游标。
谢谢!
重点在于从分区第一条数据开始计算对吧,然后就是更新,没得SqlServer以mysql为例吧, 思路是分区递归计算
CREATE TABLE t_example (
f_year INT NULL,
f_month INT NULL,
f_product_id INT NULL,
begamt INT NULL,
inamt INT NULL,
endamt INT NULL
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci;
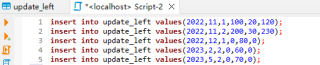
insert into t_example values(2022, 11, 1, 100, 20, 120);
insert into t_example values(2022, 11, 2, 200, 30, 230);
insert into t_example values(2022, 12, 1, 0, 80, 0);
insert into t_example values(2023, 2, 2, 0, 60, 0);
insert into t_example values(2023, 5, 2, 0, 70, 0);
with recursive CTE_PART as (
select *, ROW_NUMBER() over(partition by f_product_id order by f_year, f_month) as rn from t_example
), CTE_RECU as (
select p.f_year, p.f_month, p.f_product_id, p.begamt, p.inamt, (p.begamt + p.inamt) as endamt, p.rn from CTE_PART p where p.rn = 1 union ALL
select p1.f_year, p1.f_month, p1.f_product_id, c.endamt, p1.inamt, (c.endamt + p1.inamt) as endamt, p1.rn from CTE_PART p1, CTE_RECU c
where p1.f_product_id = c.f_product_id and p1.rn = (c.rn +1)
) update CTE_RECU c inner join t_example t
on c.f_product_id = t.f_product_id and c.f_year = t.f_year and c.f_month = t.f_month
set t.begamt = c.begamt, t.inamt = c.inamt, t.endamt = c.endamt;
可以考虑使用临时表,即排序+行号错位的思路来解。我这里没有ms的环境,就直接使用mysql了,思路是一样的。
初始化:
插入数据:
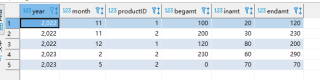
结果:
sql语句
update (
select * from
(
select
(@rownum1 := @rownum1 + 1) as rownum1,
year as temp1year,
month as temp1month,
productId as temp1productId,
begamt as temp1begamt,
inamt as temp1inamt,
endamt as temp1engamt
from
update_left ci,
(
select
@rownum1 := 0) as rn
order by
productID,
year,
month) temp1
left join (
select
(@rownum2 := @rownum2 + 1) as rownum2,
year as temp2year,
month as temp2month,
productId as temp2productId,
begamt as temp2begamt,
inamt as temp2inamt,
endamt as temp2engamt
from
update_left ci,
(
select
@rownum2 := 1) as rn
order by
productID,
year,
month
) temp2
on
temp1.rownum1 = temp2.rownum2
and temp1.temp1productId=temp2.temp2productId) temp,
update_left ul
set ul.begamt=temp.temp2engamt,ul.endamt=temp.temp2engamt+ul.inamt
where
ul.year =temp.temp1year
and ul.month =temp.temp1month
and ul.productID =temp.temp1productId
and temp.temp2productId is not null
在数据合理情况下,分析函数lag可以实现。
最后一行不知原因,可与数据有关。可参照测试,改为关联update即可。

create table dw (year int,month int,productID int,begamt int,inamt int,endamt int);
insert into dw values(2022,11,1,100,20,120);
insert into dw values(2022,11,2,200,30,230);
insert into dw values(2022,12,1,0,80,0);
insert into dw values(2023,2,2,0,60,0);
insert into dw values(2023,5,2,0,70,0);
insert into dw values(2023,6,2,0,70,0);
select
productID,year,month,
--begamt,
lag(endamt,1,0) over (partition by productID order by productID,year,month) +begamt begamt,
inamt,
--endamt
lag(endamt,1,0) over (partition by productID order by productID, year,month) +begamt+inamt endamt
from dw;
我收藏学习下,看看不用游标,用一条sql语句能写出通俗易懂,容易验证的sql
谁能告诉我那个2023年,为什么是290
为啥不用存储过程来处理?又快还节约带宽
直接用update 语句 +子查询就可以了
update tb set begamt=(select top 1 endamt from tb a where tb.productID=a.productID and tb.year+tb.month < a.year+a.month order by a.year+a.month desc )
UPDATE a SET a.begamt=b.begamt,a.endamt=b.endamt
FROM table_a as a,(select [year] as nyear,[month] as nmonth,productID as nproductID,lead(endamt,1,0) over(partition by productID order by [year] desc,[month] desc)+begamt as begamt
,lead(endamt,1,0) over(partition by productID order by [year] desc,[month] desc)+inamt+begamt as endamt
from table_a
) b
WHERE a.productID=b.nproductID and a.year=b.nyear and a.month=b.nmonth;