使用K近邻算法进行分类
问题遇到的现象和发生背景
使用K近邻算法进行分类。
要求:
补充代码,需要按照要求生成数据,并使用简单的K近邻分类器训练这些数据,最后使用训练好的分类器预测输入的点的类别。
测试说明:
输入说明:输入由四行组成,每行由一个数组成,第一行表示要生成的数据组数,第二行表示生成数据时所使用的随机状态,第三行和第四行表示待测点的特征值(待测点只有两个特征)。
输出说明,由一行组成,即输入点的类别。
注意事项:
生成数据时需要使用make_blobs函数,除了n_samples和random_state之外,要求其他参数均使用默认参数。
K均值分类器也要求均使用默认参数。
用代码块功能插入代码,请勿粘贴截图
# -*- coding: utf-8 -*-
from sklearn.datasets import make_blobs
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 请在此添加代码 完成本关任务
#
# ********** Begin *********#
# ********** End **********#
按要求完成的,输入
100
5
3
7
得到结果 [2]
可以绘图看一下分类正确与否,不需要绘图,可把25行后删除即可
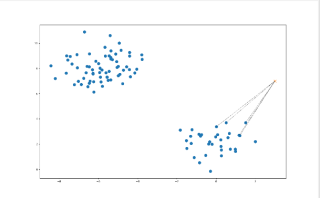
# KNeighborsClassifier进行分类demo
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
# 请在此添加代码 完成本关任务
#
# ********** Begin *********#
samples = eval(input())
state = eval(input())
feature1 = eval(input())
feature2 = eval(input())
X, y = make_blobs(n_samples=samples, random_state=state)
knn = KNeighborsClassifier()
knn.fit(X, y)
X_sample = [feature1, feature2]
X_sample = np.array(X_sample).reshape(1, -1)
print(knn.predict(X_sample))
# ********** End **********#
# 绘图看一下
from matplotlib import pyplot as plt
neighbors = knn.kneighbors(X_sample, return_distance=False) # 求出邻居节点,默认求的是5个
plt.figure(figsize=(16, 10))
plt.scatter(X[:, 0], X[:, 1], s=100, cmap='cool') # 样本
plt.scatter(X_sample[0][0], X_sample[0][1], marker="x",
s=100, cmap='cool') # 待预测的点
for i in neighbors[0]:
# 预测点与距离最近的 5 个样本的连线
plt.plot([X[i][0], X_sample[0][0]], [X[i][1], X_sample[0][1]],
'k--', linewidth=0.6);
plt.show()
- 这篇文章:使用k-近邻算法进行分类 也许有你想要的答案,你可以看看