求下述python代码计算总成绩

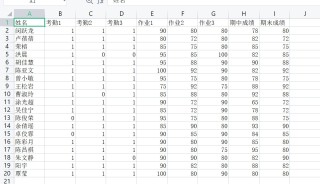
如图片所示,分别计算总成绩、班级出勤率、总成绩平均分,按图一要求编程,成绩表文件见下面的图片
初学,越简单越好
csv文件共享一下呗
班级出勤率和平均总成绩要保存在哪里?
import csv
students = {}
all_absence = 0
with open("成绩表.csv") as f:
r = csv.reader(f)
next(r)
for i in r:
absence = i[1:4].count('0')
all_absence += absence
score = 10-absence*3+eval("+".join(i[4:7]))*0.1+eval(i[7])*0.2+eval(i[8])*0.4
students[i[0]]=score
attendance_rate = round(1-all_absence/(len(students)*3))
avg_score = round(sum(students.values())/len(students))
print(f"班级出勤率:{attendance_rate*100}%")
print(f"总成绩平均分:{avg_score}")
with open("最终成绩.csv",mode='w',newline="") as f:
w = csv.writer(f)
w.writerow(("姓名","总成绩"))
w.writerows(students.items())
import pandas as pd
if __name__ == '__main__':
# gbk编码读取报错,就换成下一行utf-8的
df = pd.read_csv("文件成绩表.csv", encoding="gbk")
# df = pd.read_csv("文件成绩表.csv", encoding="utf-8")
df['总成绩'] = df['考勤1'].apply(lambda x: 10 if x == 1 else 7) \
+ df['考勤2'].apply(lambda x: 10 if x == 1 else 7) \
+ df['考勤3'].apply(lambda x: 10 if x == 1 else 7) \
+ df['作业1'].apply(lambda x: 0.2*x) \
+ df['作业2'].apply(lambda x: 0.2*x) \
+ df['作业3'].apply(lambda x: 0.2*x) \
+ df['期中成绩'].apply(lambda x: 0.2*x, 2) \
+ df['期末成绩'].apply(lambda x: 0.4*x, 2)
df['总成绩'] = df['总成绩'].apply(lambda x: round(x, 2))
df.to_csv("最终成绩.csv", index=False)
rate = round((df['考勤1'] + df['考勤2'] + df['考勤3']).sum() / (df.shape[0] * 3), 2)
avg = round(df['总成绩'].sum() / df.shape[0], 2)
df = pd.DataFrame([{"出勤率": rate, "总成绩平均分": avg}])
df.to_csv("出勤率和总成绩平均分.csv", index=False)

