如何自动获取token
目前通过浏览器——开发者工具获取网页链接,但其中关键链接的请求头中
authorizationtoken的内容都是突然出现的,在该条链接之前有两次option的预请求,请问如何通过python自动获取到authorizationtoken的内容。
链接是 https://www.sgx.com/zh-hans/securities/company-announcements
F12获取到的列表如下:
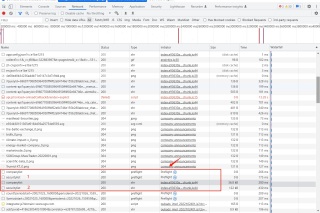
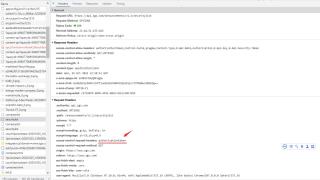
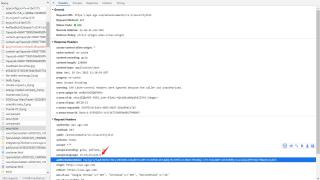
我使用上图这个authorizationtoken:
OepJg2iyYwqB7XGSh/98cy2UbED0nu1VwdKEInz0PzSSIKN5Bs2KIqWmj20sE04hioC20wtC5MLBDqi/2ttJZQsAmBrvnBJbVQMyJLosouAjwjMThSQLfbNqX5yoyNih
通过python,写好相应内容,是能获取到内容的,但这个authorizationtoken只是临时性的,不可能每次F12,获取到authorizationtoken再手动运行爬虫。
我知道很多网站请求时或者登陆时会有相应字段,但我需要的这个网址,我按上面的办法是没有token的,所以想请教下大家,有什么办法自动获取到我所说的地址里的authorizationtoken吗?谢谢!
经过对压缩混淆的js代码进行分析,得到了加密函数,具体流程如下
- 首先访问 https://www.sgx.com/config/appconfig.json?v=e1be1215 获取"CMS_VERSION"
- 再访问 https://api2.sgx.com/content-api/?queryId=%22CMS_VERSION%22:we_chat_qr_validator ,得到"qrValidator"
- 接着用加密函数对qrValidator加密,就可以得到 authorizationtoken
authorizationtoken = qrValidator.replace(/[a-zA-Z]/g,(function(t){var e=t.charCodeAt(0)+13;return String.fromCharCode((t<="Z"?90:122)>=e?e:e-26)})))
python代码如下
import requests
import re
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
response = requests.get("https://www.sgx.com/config/appconfig.json?v=e1be1215", headers = headers)
CMS_VERSION = response.json()["CMS_VERSION"]
response = requests.get("https://api2.sgx.com/content-api/?queryId=" + CMS_VERSION + ":we_chat_qr_validator", headers = headers)
qrValidator = response.json()["data"]["qrValidator"]
def encrypt(t):
e = ord(t) + 13
code = e if ((90 if t<="Z" else 122) >=e) else e-26
return chr(code)
print(qrValidator)
authorizationtoken=""
for t in qrValidator:
authorizationtoken += (encrypt(t) if re.match("[a-zA-Z]", t) else t)
print(authorizationtoken)
import requests
import js2py
response = requests.get(
'https://api2.sgx.com/content-api/?queryId=69607708850964950ff4f02e84746e155b288abb:we_chat_qr_validator')
json = response.json()
print(json)
code = json['data']['qrValidator']
print(code)
code = js2py.eval_js("""function test(a){
a=a.replace(/[a-zA-Z]/g, (function (t) {
var e = t.charCodeAt(0) + 13;
return String.fromCharCode((t <= "Z" ? 90 : 122) >= e ? e : e - 26)
}))
return a
}
""")(code)
response = requests.get('https://api.sgx.com/announcements/v1.1/securitylist', headers={'authorizationtoken': code})
json = response.json()
print(json)
直接用selenium去爬虫可以省很多事情
这个有点难,可能还在js中部分加密算法, 不好搞
多久刷新呀?我大概看了一下这个能用的时间还是挺久的,全局搜索在一个js文件中有这个,可以试试逆向产生这个东西,应该还是有点难度的,我试试看
https://www.sgx.com/index.e93630aff47c79070072.chunk.js
这个是产生这个东西的js链接
不用试了,11万行的js,用的开源js项目,提取了一部分,花了两个小时,没逆向出来,我前端水平有限😂
这边观察了一下,这个authtoken同一个电脑不会变哇,你要换台电脑,直接复制一次性就能用呀,不是动态更新的。
跟楼上差不多吧! python发送完登录请求,可能需要加判断,对正文的字符串进行处理分割获取token值,然后赋个值,记得下次请求头里加一下
嗯,我看了下,觉得这种方式,可以作为参考,期望对你有所帮助:
【从cookie中获取Authorization信息】链接1:https://www.baidu.com/link?url=74XYB7tCIrkKd5_aa3oTBdU8DjBNFmGmSY_1FNMyYhzebE9QxKP_QWqqt9ISnXbbMc2gKEFC2kuuUJQ5wRVTZK&wd=&eqid=e08719cf000c92700000000663595503