爬虫 POST请求 获取网页标题内容
网上搜索使用requests.post() 方法 的案例都是 教你 如何爬取翻译的内容
请问怎么使用 requests.post() 方法 向搜索引擎 提交搜索内容 并获取到搜索的数据呢?
使用requests.get()方法 搜索内容 并获取 是学会了 如果换成post() 方法 又如何操作? 下面是我写的get()方法
from unittest import result
import requests
import re
url = "https://www.必应.com/search?q=蔷薇花墙纸"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37"
}
resp = requests.get(url=url, headers=headers)
resp.encoding = 'utf-8'
# 正则表达式准备
obj1 = re.compile(
r'<li class=".*?">.*?<h2><a target="_blank" .*?">(?P<a>.*?)</a>.*?<div class=".*?">.*?<cite>(?P<z>.*?)</cite>', re.S)
result = obj1.finditer(resp.text)
for it in result:
ii = it.group("a")
i1 = re.sub("[A-Za-z<>/]", "", ii) # 去除<strong>和</strong>
print(i1)
print(it.group("z"))
resp.close() # 关闭resp
运行结果:
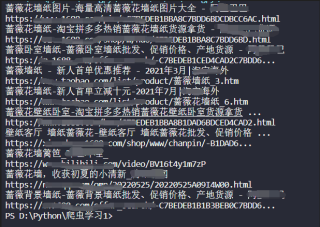
如果换成post() 方法怎么样写才能获取 搜索 蔷薇花墙纸 的网站标题和网址呢?
#这个post() 方法 不会写了
from urllib import response
import requests
url = "https://www.必应.com"
search = {"qry": "蔷薇花墙纸"}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37"
}
response_1 = requests.post(url,data=search,headers=headers)
response_1.encoding = 'utf-8'
print(response_1.text)
想要达到的结果: post() 方法 获取
post和get方法的使用不是你决定的,二十接口使用的是什么请求方式,如果它是get请求那就只能用get请求,是post就只能用post