爬虫构建网页 获取不了多个网页
以下这一段,是我进行新闻汽车之家爬取时,需要构建网页,步长为10,即第一页是0,第二页是10,第三页是20,以此类推。我执行以下代码是获取了第一位i,即0,获取了第一页的网址。但是第二页,第三页获取不了 这是为什么啊
import requests
from bs4 import BeautifulSoup
urls=[]
for i in range(0,4,10):
url="https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E6%96%B0%E9%97%BB%E6%B1%BD%E8%BD%A6%E4%B9%8B%E5%AE%B6&cl=2&x_bfe_rqs=032000000000000000000000000000000000000000000008&x_bfe_tjscore=0.080000&tngroupname=organic_news&newVideo=12&goods_entry_switch=1&rsv_dl=news_b_pn&pn={}%22.format(i)
urls.append(url)
print(urls)
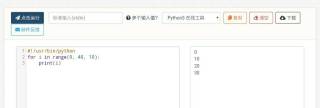
range(0,41,10)分别得到0,10,20,30,40
range三个参数意思分别是:start开始,end结束,step步长