Python 使用sklearn K-means聚类如何输出每个簇中的具体数据
如题,使用sklearn的k-means进行聚类分析, 要如何输出每个group中的具体数据呢?
遍历一下它给的label_,然后用值作为key,用下标作为value,字典的value做成一个list,下标直接append
- 这篇文章:K-Means 聚类算法 python sklearn 也许有你想要的答案,你可以看看
- 同时,你还可以查看手册:K-means聚类法 中的内容
- 除此之外, 这篇博客: Python:Sklearn的K-Means以及均值漂移聚类代码中的 K-Means聚类 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
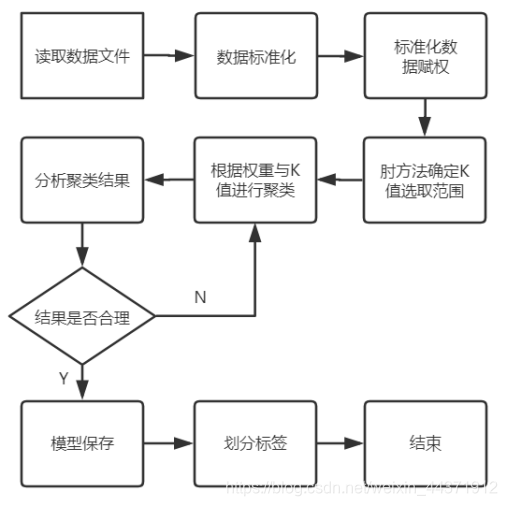
聚类流程图如上图所示,K-Means聚类需要自己设置簇数k,可以通过肘方法确定k值。import pandas as pd import numpy as np import matplotlib from matplotlib import pyplot as plt from pandas import DataFrame,Series from sklearn.externals import joblib #读取文件夹 data = pd.read_csv('train.csv',encoding = "gbk") #将数据用(二维)数组的形式表示 dataset_1= data[['属性1','属性2','属性3']] dataset_1 = dataset_1.values #对数据进行标准化 from sklearn.preprocessing import StandardScaler # 导入标准化模块 ss = StandardScaler() std_data = ss.fit_transform(dataset_1) # 导入“cluster”模块 from sklearn import cluster # 创建KMeans模型 clf = cluster.KMeans(init='k-means++', n_clusters=10, random_state=42) clf.fit(std_data) # 模型保存 # joblib.dump(clf,"train_2.m") clu_l = clf.labels_ clu_c = clf.cluster_centers_ print("簇数:",len(clu_c)) #获取簇数 print("质心坐标:",clu_c) #获取标准化质心坐标 print("原质心坐标为:",ss.inverse_transform(clu_c)) # 获取原质心坐标 print("聚类对应标签为:",clu_l) #获取所有标签 # 统计每个簇的点有多少个。 dict = {0:0,1:0,2:0,3:0,4:0,5:0,6:0,7:0,8:0,9:0,10:0,11:0,12:0,13:0,14:0,15:0} for i in clu_l: dict[i] = dict[i]+1 print("每个簇内点数为:",dict) import sklearn.metrics as sm # 计算 轮廓系数,CH 指标,DBI s1 = sm.silhouette_score(std_data, clu_l, metric='euclidean') # 计算轮廓系数 s2 = sm.calinski_harabasz_score(std_data, clu_l) # 计算CH score s3 = sm.davies_bouldin_score(std_data, clu_l) # 计算 DBI print("轮廓系数:",s1) print("ch score:",s2) print("DBI:",s3)