python处理tsv文件矩阵
现有一个矩阵(tsv文件),行名为ENSG开头+数字编号
前五行五列情况如图
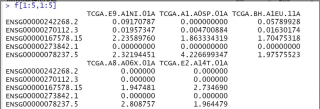
现已知行名中,小数点前数值出现重复,小数点后数值不同,
现需要保留小数点后数值最大的行名,去除其他小数点后数值更小的行名
例如:行名为7700.1 7700.2 7700.5的三行,仅保留7700.5所在行
输出一个行名没有重复的新矩阵,列名不变
思路:字符串分割后分组,分组后比较排序后筛选剔除
import pandas as pd
df = pd.read_csv('xxxx.tsv', sep='\t')
df['tempOne'] = df['A'].apply(lambda x: x.split(".")[0])
df['tempTwo'] = df['A'].apply(lambda x: int(x.split(".")[1]))
df_new = df.iloc[df.groupby('tempOne').apply(lambda o: o['tempTwo'].idxmax())]
df_new.drop(['tempOne', 'tempTwo'], axis=1, inplace=True)
源数据:

结果:

文件发我邮箱383817842@qq.com,我给你搞
import pandas as pd
import pandasql as ps
df = pd.DataFrame({"A": ['ENSG0002.14', 'ENSG0002.8', 'ENSG0003.18', 'ENSG0006.1'],
"B": ['B4', 'B5', 'B6', 'B7'],
"C": ['C4', 'C5', 'C6', 'C7'],
"D": ['D4', 'D5', 'D6', 'D7'],
"F": ['F4', 'F5', 'F6', 'F7']}
)
sql = """SELECT * FROM df as t
WHERE
NOT EXISTS(SELECT 1 FROM df WHERE
SUBSTR(A,1,INSTR(A,'.')-1)= SUBSTR(T.A,1,INSTR(T.A,'.')-1)
AND
CAST(SUBSTR(A,INSTR(A,'.')+1, LENGTH(A)-INSTR(A,'.')) as int) >CAST(SUBSTR(t.A,INSTR(t.a,'.')+1,LENGTH(t.A)-INSTR(t.A,'.')) as int)
)
"""
f = lambda x: ps.sqldf(x, globals())
print(f(sql))
--result
A B C D F
0 ENSG0002.14 B4 C4 D4 F4
1 ENSG0003.18 B6 C6 D6 F6
2 ENSG0006.1 B7 C7 D7 F7
- 这篇文章:Python读取tsv文件数据 也许有你想要的答案,你可以看看
使用pandas 列取最大值