python爬取网页题库如何将选项一一对应
python爬取网页题目 选项怎么一一对应
用代码块功能插入代码,请勿粘贴截图
import requests
import re
url_list = []
option_one = []
option_two = []
op = []
for i in range(21112, 21114):
url = "http://kjds.52jingsai.com/reviewx.php?snum={}".format(i)
# 模拟浏览器的访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'Cookie': 'PHPSESSID=698octtqm0auki0ol0lhnaom5u; qqopenid=63F6832C8BDB537EB8472808AA00F409; qqnick=%B6%A5%BC%B6%F2%E5%F2%EF'}
res = requests.get(url, headers=headers)
if res.status_code == 200:
# 1.获取网页源代码
raw_text = res.text
# 正则表达式
re_res = re.findall(
r'(.*?)(.*?)
(.*?)', raw_text,
re.DOTALL) # 题目
op1 = re.findall(r'(.*?)', raw_text, re.DOTALL) # 选项
op2 = re.findall(r'(.*?)', raw_text, re.DOTALL) # 答案
# 检查打印获取到的信息
url_list.extend(re_res) # 打印题目
option_one.extend(op1) # 打印选项
option_two.extend(op2) # 打印答案
op.extend(op1 + op2) # 选项和答案一一对应
print(url_list)
print(len(url_list))
print(op)
题目是前20道题是判断题后40到题是选择题,且判断题没有abcd只有对错两个选项,我输出的结果会先输出对错然后输出abcd再输出选项


尝试过用zip函数 但是输出结果是 ’对:A ‘ ’错:B‘
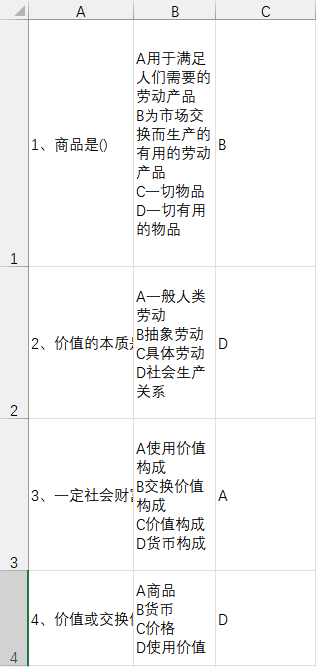
我想要达到的结果
拿去
import requests
from bs4 import BeautifulSoup
url_list = []
option_one = []
option_two = []
op = []
for i in range(21112, 21114):
url = "http://kjds.52jingsai.com/reviewx.php?snum={}".format(i)
# 模拟浏览器的访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'Cookie': 'PHPSESSID=698octtqm0auki0ol0lhnaom5u; qqopenid=63F6832C8BDB537EB8472808AA00F409; qqnick=%B6%A5%BC%B6%F2%E5%F2%EF'}
res = requests.get(url, headers=headers)
if res.status_code == 200:
# 1.获取网页源代码
raw_text = res.text
# with open('mybaidu.html', 'w', encoding="utf-8") as f:
# f.write(raw_text)
soup = BeautifulSoup(raw_text,'lxml') # 设置解析库为
res = soup.select('div[class="subject_item"]')
for i in res:
print(i.findNext(attrs={"class":"subject_title"}).text)
for j in i.findNext(attrs={"class":"choose_answer"}).findAll(attrs={"class":"a_1"}):
print(j.text)
print("\n")