Python爬虫.*?匹配时的疑惑
Python爬虫.*?匹配时的疑惑
网页源代码是这样的
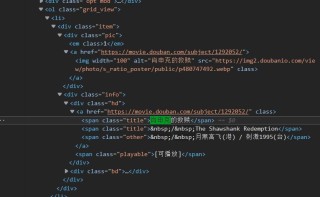
这样过滤时r'<span class="title">(?P<name>.*?)</span>',re.S
会得到
”肖申克的救赎“
” / The Shawshank Redemption“
这两串
而如果在前面加上'<div class="item">*?
就能过滤掉后面的” / The Shawshank Redemption“这一串
我们知道.?是从<内容1>?<内容二>从前往后匹配过去,所以为什么在前面添加的过滤能滤掉后面的内容?
在span class="title"前面添加div class="item"过滤并显示内容
import requests
import re
url = "https://movie.douban.com/top250"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42"
}
resp = requests.get(url,headers=headers)
web_code = resp.text
obj = re.compile(r'<div class="item">(?P<grb>.*?)<span class="title">(?P<name>.*?)</span>',re.S)
result = obj.finditer(web_code)
for i in result:
print(i.group("grb"))
print(i.group("name"))
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
肖申克的救赎
#可以看到<div class="item">(?P<grb>.*?)过滤的内容里并不包含” / The Shawshank Redemption“这一串
但是如果前面不添加添加div class="item"
obj = re.compile(r'<span class="title">(?P<name>.*?)</span>',re.S)
result = obj.finditer(web_code)
for i in result:
print(i.group("name"))
肖申克的救赎
/ The Shawshank Redemption
#结果后面就多了 / The Shawshank Redemption这一串
请问<div class="item">(?P<grb>.*?)<span class="title">(?P<name>.*?)</span>中的
<div class="item">(?P<grb>.*?)是怎么做到过滤掉”肖申克的救赎“后面的
” / The Shawshank Redemption“这一串的?
.*?
点代表任意字符
星表示前面的字符重复任意次数
点星就表示任意长度的字符串
问号表示非贪婪匹配,也就是匹配到第一个能跟后续字符匹配的字符串就结束
-=-=-=
那么好了,两个匹配,一个是item.*?title.*?,一个只有title.*?
后一个当然会匹配所有title开头的字符串
而前一个,必须先匹配到item,再匹配title,才会拿取后续字符串,而你后一个字符串不再是item开头了,于是不再匹配
这里敲重点,每次匹配,都是从前一个匹配之后继续往后匹配的,不会再从头到尾的去匹配
前面添加 div class=item时,说明你正则表达式的开头变了呀,你只能匹配到第一行的内容呀,具备这个开头和结尾的只能是第一行呀!
有帮助的话采纳一下哦!
因为你只获取了前两个分组,如果后面继续获取的话还是会出现 ” / The Shawshank Redemption“这一串的

obj = re.compile(r'<span class="title">(?P<name>.*?)</span>',re.S) 这个模式是可以匹配到两个的,就是下图红框中两个,两个匹配中的name分别就是“肖申克的救赎”和“ / The Shawshank Redemption”:

obj = re.compile(r'<div class="item">(?P<grb>.*?)<span class="title">(?P<name>.*?)</span>',re.S)这个模式可以匹配到一个,是下图红框的部分,在这个匹配中,grb是黄色框部分,name是蓝色框部分,也就是“肖申克的救赎”:
