python爬虫使用re.findall(re.compile 筛不出数据!
这是我的代码
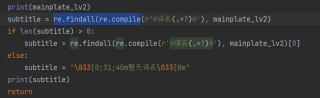
这是输出的mainplate_v2 我肉眼都可见的数据 但 程序抓不到
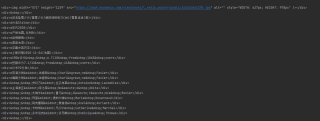
我要抓取 ◎译名 (?) ◎ 中间的数据 却拿不到 不知道为啥
<div>◎译名内容内容内容内容内容</div>
<div>◎片名内容</div>
规避版权问题 我把数据 写成 内容二字了
这是跨行匹配, .*默认是不匹配换行符的,所以匹配不到,确实需要加上re.S:
re.findall(re.compile(r'◎译名(.*?)◎', re.S), mainplate_lv2)
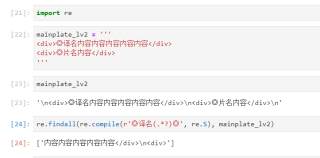
正则表达式写为
<div>@(.*?)</div>
试试,这种HTML结构建议用xpath匹配,正则表达式更适合匹配js里的内容
前面有圈,后面没有圈啊

re.compile(r'◎译名(.*?)</div>')
- 你看下这篇博客吧, 应该有用👉 :python中正则表达式 re.findall 用法