同样一张2080Ti,跑30G的bisenet轻轻松松,反而跑十几G的更轻量化的网络就跑不动了?
同样一张2080Ti,跑30G的bisenet轻轻松松,反而跑十几G的更轻量化的网络就跑不动了,会不会因为深度可分离卷积和非对称卷积这些pytorch没有优化呢? 比如我一张2080ti,512x1024下bisenetv2可以bs=4,反而跑今年TMM一篇flops只有十G的FBSnet 两张2080ti都跑不起?
原因很多,不知道具体情况不好说。并不是说网络参数越多就一定占用显存越多。
显存是和计算量相关的,并且计算完毕之后这块显存是否释放也有关系的。
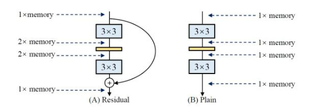
拿ResNet举个例子来说,简单的卷积层计算完output之后就将前面的显存释放掉了,但是如果你想跨层跳跃链接(skip connection),你就得等下面的连接计算完毕才能释放这部分资源,而且分支越多这种资源占用就越久,这还是CNN,要是像RNN的那种开销更大。
另外还有池化,采样这些层是不计算参数量的,但是也要占用显存的啊,越多这种操作就占用越多的显存。
而在数据结构里面,有一招空间换时间的用法,而显卡的并行专门干的就是空间换时间,所以很多模型表面上参数量FLOPS特小,计算和训练都很快,但是这个是用空间换时间,代价就是显存占用高。