windows和Linux运行不一致
问题遇到的现象和发生背景
selenium抓取数据windows上运行正常,linux上就被识别到了
用代码块功能插入代码,请勿粘贴截图
import sys
sys.path.append("../../")
from utils.user_web import WEB_TOOLS
wt = WEB_TOOLS()
url = "http://wh.zufang.zhuge.com/1003664/4115982.html%22
download_path = "./"
spider_name = 0
is_proxy = 0
sleep_time = 10
driver = wt.get_page_seconds(url, download_path, spider_name, is_proxy, sleep_time)
print(driver.page_source)
运行结果及报错内容
在windows上能正常打印网页信息,但是局域网的Linux系统就被识别到了,直接跳转到验证码环境了,实际是没有验证码的
我的解答思路和尝试过的方法
尝试过修改WEB_TOOLS公共类的selenium参数,但是没有多大效果,公共类截图
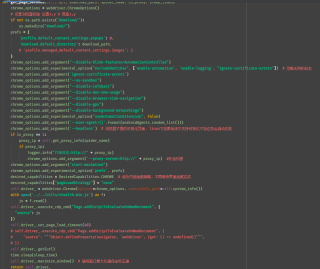
我想要达到的结果
windows和Linux运行结果一致
有些网站就是根据是否是有头无头检测的,linux本来就不能有头,所以这个没啥太好的办法,只能在windows机器跑