pandas 中zip的使用
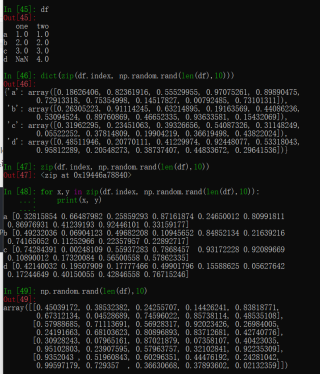
最后一行代码啥意思,zip里面,users_ratings.index不是就一维吗,后面np.random.rand(len(users_ratings),10).astype(np.float32) 应该是二维,调用zip发生了啥,然后外面再套一层就是把这个转换为字典是吧?主要是调用zip时发生了啥,我以前用zip函数都是同样的维度
dtype=[('userId',np.int32),('movieId',np.int32),('rating',np.float32)]
dataset=pd.read_csv(DATA_PATH,usecols=range(3),dtype=dtype) # 读取csv文件
users_ratings=dataset.groupby('userId').agg([list])
P = dict(zip(users_ratings.index,np.random.rand(len(users_ratings),10).astype(np.float32)
))
print(users_ratings),对于users_ratings输出如下

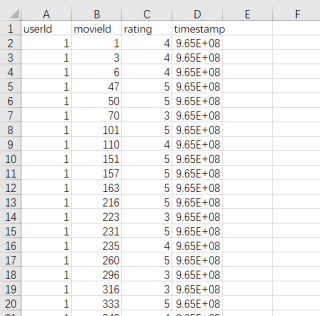
csv文件数据如下
其实是同样的原理,zip会把可迭代对象对应位置的元素组合成一个元组,你这里的zip里面第二个参数虽然是二维的,但也可以看作是一维数组的数组,每个元素是一个一维数组,这样子应该就好理解了吧。zip把第一个可迭代对象的值和第二个可迭代对象对应位置的一维数组组合成元组,结果是一个元组列表,再传递给dict,生成一个字典,字典的key为元组第一个元素,其value为相应元组的第二个元素