Tensorflow 图神经训练出错 TypeError: Failed to convert object of type SparseTensor'> to Tensor
做图神经网络训练,python 3.6, tensorflow version: 2.6.2, keras version 2.6.0. 一直报错,希望有专家能帮帮我。 出错的代码是第67行, 就是这个。 需要具体改哪行代码?
model.fit(model_input, y_train, sample_weight=train_mask, validation_data=val_data, batch_size=A.shape[0], epochs=NB_EPOCH, shuffle=False, verbose=2, callbacks=[mc_callback])
TypeError: Failed to convert object of type <class 'tensorflow.python.framework.sparse_tensor.SparseTensor'> to Tensor. Contents: SparseTensor(indices=Tensor("DeserializeSparse:0", shape=(None, 2), dtype=int64), values=Tensor("DeserializeSparse:1", shape=(None,), dtype=float32), dense_shape=Tensor("stack:0", shape=(2,), dtype=int64)). Consider casting elements to a supported type.

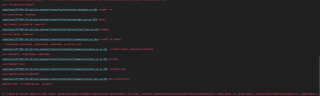
#!/usr/bin/env python
# coding: utf-8
import numpy as np
import tensorflow
from tensorflow.python.keras.callbacks import ModelCheckpoint
from tensorflow.python.keras.layers import Lambda
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.optimizer_v1 import adam
from tensorflow.python.keras.optimizers import adam_v2
import tensorflow as tf
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from gcn import GCN
from utils import preprocess_adj, plot_embeddings, load_data_v1
if __name__ == "__main__":
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if len(physical_devices) > 0:
for k in range(len(physical_devices)):
tf.config.experimental.set_memory_growth(physical_devices[k], True)
print('memory growth:', tf.config.experimental.get_memory_growth(physical_devices[k]))
else:
print("Not enough GPU hardware devices available")
FEATURE_LESS = False
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
A, features, y_train, y_val, y_test, train_mask, val_mask, test_mask = load_data_v1(
'cora')
A = preprocess_adj(A)
features /= features.sum(axis=1, ).reshape(-1, 1)
if FEATURE_LESS:
X = np.arange(A.shape[-1])
feature_dim = A.shape[-1]
else:
X = features
feature_dim = X.shape[-1]
model_input = [X, A]
# Compile model
model = GCN(A.shape[-1], feature_dim, 16, y_train.shape[1], dropout_rate=0.5, l2_reg=2.5e-4,
feature_less=FEATURE_LESS, )
model.compile(optimizer=adam_v2.Adam(0.01), loss='categorical_crossentropy',
weighted_metrics=['categorical_crossentropy', 'acc'])
NB_EPOCH = 200
PATIENCE = 200 # early stopping patience
val_data = (model_input, y_val, val_mask)
mc_callback = ModelCheckpoint('./best_model.h5',
monitor='val_weighted_categorical_crossentropy',
save_best_only=True,
save_weights_only=True)
# train
print("start training")
model.fit(model_input, y_train, sample_weight=train_mask, validation_data=val_data, batch_size=A.shape[0], epochs=NB_EPOCH, shuffle=False, verbose=2,
callbacks=[mc_callback])
# test
model.load_weights('./best_model.h5')
eval_results = model.evaluate(
model_input, y_test, sample_weight=test_mask, batch_size=A.shape[0])
print('Done.\n'
'Test loss: {}\n'
'Test weighted_loss: {}\n'
'Test accuracy: {}'.format(*eval_results))
embedding_model = Model(model.input, outputs=Lambda(lambda x: model.layers[-1].output)(model.input))
embedding_weights = embedding_model.predict(model_input, batch_size=A.shape[0])
y = np.genfromtxt("{}{}.content".format('../data/cora/', 'cora'), dtype=np.dtype(str))[:, -1]
plot_embeddings(embedding_weights, np.arange(A.shape[0]), y)
sparse_tensor和tensor转换出问题了,tf.convert_to_tensor_or_sparse_tensor用这个函数转换一下
有专家吗