python scatter
python scatter
python matplotlib scatter作图
问题相关代码,请勿粘贴截图
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
x = np.array(li).reshape(-1,1)
print(x)
km = KMeans(n_clusters=3,max_iter=1000).fit(x)
Muk = km.cluster_centers_
print(Muk[:, 0])
Muk = [[13,40],[34,28],[61,12]]
y = KMeans(n_clusters=3,max_iter=1000).fit_predict(x) #会得出每个sample属于哪一类
C_i = km.predict(x)
print(C_i)
f, ax = plt.subplots(figsize=(7, 5))
colors = ['r', 'g', 'b']
for i in range(3):
ax.scatter(time_arr, day_arr, c=C_i,label="Cluster {}".format(i))
ax.scatter([13,34,61],[40,28,12], s=100, color='red',label='Center')
ax.set_title("eat")
ax.legend()
f.show()
运行结果及报错内容
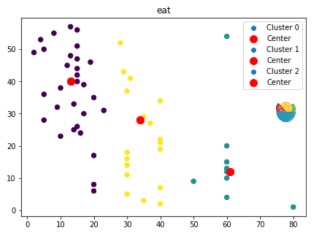
我想要达到的结果
把右上标改成正确的
你给出的代码是不完整的吧?
x = np.array(li).reshape(-1,1) # 这一句这里的li都没有定义
- 你看下这篇博客吧, 应该有用👉 :Python使用scatter函数绘制点在线的上层
请将代码置于代码框中
# 画图包
from matplotlib import pyplot as plt
# 封装好的KMeans聚类包
from sklearn.cluster import KMeans
import numpy as np
x = np.array(li).reshape(-1,1)
# print(x)
km = KMeans(n_clusters=3,max_iter=1000).fit(x)
Muk = km.cluster_centers_
print(Muk[:, 0])
Muk = [[13,40],[34,28],[61,12]]
y = KMeans(n_clusters=3,max_iter=1000).fit_predict(x) #会得出每个sample属于哪一类
C_i = km.predict(x)
print(C_i)
# plt.scatter(time_arr,day_arr,c=C_i,cmap=plt.cm.Paired)
# label = array(C_i)
# plt.scatter(time_arr, day_arr,15.0*label,15.0*label)
# # with legend
# f2 = plt.figure(2)
# idx_1 = find(label==0)
# p1 = plt.scatter(x[idx_1,1], x[idx_1,0], marker = 'x', color = 'm', label='1', s = 30)
# idx_2 = find(label==1)
# p2 = plt.scatter(x[idx_2,1], x[idx_2,0], marker = '+', color = 'c', label='2', s = 50)
# idx_3 = find(label==2)
# p3 = plt.scatter(x[idx_3,1], x[idx_3,0], marker = 'o', color = 'r', label='3', s = 15)
# plt.legend(loc = 'upper right')
f, ax = plt.subplots(figsize=(7, 5))
colors = ['r', 'g', 'b']
for i in range(3):
# p = blobs[ground_truth == i/]
ax.scatter(time_arr, day_arr, c=C_i,label="Cluster {}".format(i))
ax.scatter([13,34,61],[40,28,12], s=100, color='red',label='Center')
ax.set_title("eat")
ax.legend()
f.show()