特征集矩阵太大,内存不够,提取不了
问题遇到的现象和发生背景
在提取语音数据特征时,一条语音数据.wav特征为(M,N)维,再创建一个(n,M,N)的矩阵来存放n条语音特征集,但是这样操作存在一个问题就是这样得到的矩阵太大
问题相关代码,请勿粘贴截图
audio_duration = 3
sampling_rate = 44100
input_length = sampling_rate * audio_duration
n_mfcc = 20
data_sample = np.zeros(input_length)
MFCC = librosa.feature.mfcc(data_sample, sr=sampling_rate, n_mfcc=n_mfcc)
audios = np.empty(shape=(128, 255, 50000, 1), dtype='float32')
emotion_labels = []
counter = 0
for file in glob.glob("E:/ser0002///*.wav"):
file_name = os.path.basename(file)
emotion_labels.append(file_name.split("-")[2])
emotion = emotions[file_name.split("-")[2]]
signals, sample_rate = librosa.load(file, res_type='kaiser_fast', sr=22050 * 2)
signals, index = librosa.effects.trim(signals, top_db=25) # 移除开始和结尾的静音
signals = signal.wiener(signals)
运行结果及报错内容
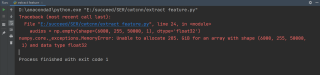
我的解答思路和尝试过的方法
(1)有没有什么办法是,读一条就存一条最后把6000条都存起来
(2)使用keras 提供的 DataGenerator,DataGenerator只是把特征集分批次的送入模块,而我的特征集还没有提出来
用代码快提交代码
参考下这个
https://www.jb51.net/article/200061.htm
你这也太大了吧,我以前也遇到过类似的,
我一开始的想法是改变数据类型,但是作用不大,然后就是将数据分批计算,然后存起来,最后再合并起来,要麻烦不少,我是花了好长时间才解决,不过我感觉这样解决问题实属是下下策