java 提取pdf/word文件内容,需要保持原文排版提取
java 提取pdf/word文件内容,需要保持原文排版提取
下面的测试文件地址
https://hzaihe-1304269943.cos.ap-shanghai.myqcloud.com/markdown/csdn.docx
https://hzaihe-1304269943.cos.ap-shanghai.myqcloud.com/markdown/csdn.pdf
难点说明:在读取文件的时候无法做到一行一行的读取 并且在读取的时候能够判断出来当前的元素属性是否是表格 文字 图片 等,只能单一的提取 由于表格中的内容也是文字 在文字提取的时候就会把表格的文字提取出来,而使用表格提取的话可以精表格中的内容出来但文字就会丢失,下面是我通过两种方式提取的内容,表格做了分割处理
我的解答思路和尝试过的方法,我尝试过多种方法来解决这个问题 希望能够循环读取每一页文件的每一行元素,但尝试了好多都没有这些方法,也想过将文件转换成XML来解决通过标签来解决,但最后失败了
提取纯文字(这不是我想要的,应为把表格也提取出来了,只希望到2. 今天确实不错 结束)
测试文件
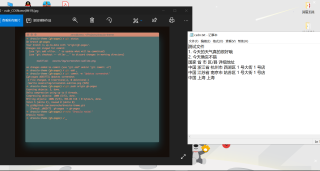
1. 今天的天气真的很好哦
2. 今天确实不错
国家 省 市 区/县 详细地址
中国 浙江省 杭州市 西湖区 1 号大街 1 号店
中国 江苏省 南京市 姑苏区 1 号大街 1 号店
中国 上海 上海
提取表格
[
{
"textList":[
{
"rowId":"1_1",
"text":"国家"
},
{
"rowId":"1_2",
"text":"省"
},
{
"rowId":"1_3",
"text":"市"
},
{
"rowId":"1_4",
"text":"区/县"
},
{
"rowId":"1_5",
"text":"详细地址"
},
{
"rowId":"2_1",
"text":"中国"
},
{
"rowId":"2_2",
"text":"浙江省"
},
{
"rowId":"2_3",
"text":"杭州市"
},
{
"rowId":"2_4",
"text":"西湖区"
},
{
"rowId":"2_5",
"text":"1号大街1号店"
},
{
"rowId":"3_1",
"text":"中国"
},
{
"rowId":"3_2",
"text":"江苏省"
},
{
"rowId":"3_3",
"text":"南京市"
},
{
"rowId":"3_4",
"text":"姑苏区"
},
{
"rowId":"3_5",
"text":"1号大街1号店"
},
{
"rowId":"4_1",
"text":"中国"
},
{
"rowId":"4_2",
"text":"上海"
},
{
"rowId":"4_3",
"text":"上海"
}
],
"type":"table",
"id":1
}
]
最终我希望的结果是能保持和原文一样的排版并且能标明当前的内容是文字 表格 图片的形式
我测的是PDF
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import org.apache.pdfbox.text.PDFTextStripper;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.Iterator;
/**
* @program: extract-PDF
* @description:
* @author: manhengwei1
* @create: 2022-09-02 16:46
**/
public class PDFUtil {
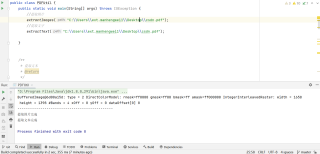
public static void main(String[] args) throws IOException {
//提取图片
extractImages("C:\\Users\\ext.manhengwei1\\Desktop\\csdn.pdf");
//提取文字
extractText("C:\\Users\\ext.manhengwei1\\Desktop\\csdn.pdf");
}
/**
* 提取文本
* @return
*/
public static void extractText(String path){
try {
File fdf = new File(path);
//通过文件名加载文档
PDDocument pdd = Loader.loadPDF(fdf);
//获取文档的页数
int pageNumber = pdd.getNumberOfPages();
//剥离器(读取pdf文件)
PDFTextStripper stripper = new PDFTextStripper();
//排序
stripper.setSortByPosition(true);
//设置要读取的起始页码
stripper.setStartPage(1);
//设置要读取的结束页码
stripper.setEndPage(pageNumber);
// System.out.println(stripper.getText(pdd));
//生成的txt的文件路径
String docPath =path.substring(0,path.lastIndexOf("."))+".txt";
File doc = new File(docPath);
if(!doc.exists()){
doc.createNewFile();
}
//文件输出流
FileOutputStream fos = new FileOutputStream(doc);
Writer writer = new OutputStreamWriter(fos, "utf-8");
stripper.writeText(pdd, writer);
writer.close();
fos.close();
System.out.println("提取文本完成");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 提取图片
* @return
*/
public static boolean extractImages(String path) {
boolean result = true;
try{
File fdf = new File(path);
//通过文件名加载文档
PDDocument document = Loader.loadPDF(fdf);
PDPageTree pages = document.getPages();
Iterator<PDPage> iter = pages.iterator();
//生成的txt的文件路径
String imagePath =path.substring(0,path.lastIndexOf("."));
while(iter.hasNext()){
PDPage page = iter.next();
PDResources resources =page.getResources();
resources.getXObjectNames().forEach(e->{
try {
if(resources.isImageXObject(e)){
PDImageXObject imageXObject=(PDImageXObject)resources.getXObject(e);
BufferedImage bufferedImage= imageXObject.getImage();
System.out.println(bufferedImage);
ImageIO.write(bufferedImage,"jpg",new File(imagePath+"_"+e+".jpg"));
}
} catch (IOException ioException) {
ioException.printStackTrace();
}
});
System.out.println("----------------------------------------------");
}
System.out.println("提取图片完成");
// document.save(fdf);
document.close();
} catch(IOException ex){
ex.printStackTrace();
return false;
}
return result;
}
}
效果:
可以试试spire.doc和spire.pdf,基本能保留原文排版。如果要在同一个程序中用它们,需要用spire.office
文档:
Java 提取或读取 PDF 文本内容
Java 提取 Word 中的文本和图片