pandas处理有条件的合并
本人在使用pandas处理一些数据时不知如何操作:(数据量比较大)
我需要将两个dataframe进行处理,两个dataframe的title大部分都是相等的,对于两个df中相同的title,我需要提取出两个dataframe中my_score值较高的一个,最终两个dataframe经过处理后能生成一个心的df,这个df就是包含了初始的两个df中title相同且my_scrore分数较高的所有元素
(可能问题描述不是很清楚,可以与我交流)
以下为相关的内容:
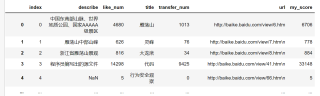
df1:
df2
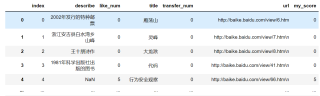
比如说df1的title为雁荡山的item,my_score为6706 > df2中的0,所以生成的df第一条为df1中的雁荡山条目,以此类推(df2中my_score并不都是0)
之前这个问题放了一段时间,现在还是找到了一个比较笨拙的方法,
ret_df_1 = pd.DataFrame(columns=['index','describe','like_num','title','transfer_num','url','my_score' ])
count = 1
for my_score in my_df_1['my_score']:
other_score = other_df_1['my_score'][count]
if my_score >= other_score:
ret_df_1 = ret_df_1.append(pd.DataFrame(my_df_1.iloc[count, :]).T)
else:
ret_df_1 = ret_df_1.append(pd.DataFrame(other_df_1.iloc[count, :]).T)
if count<19:
count += 1
ret_df_1
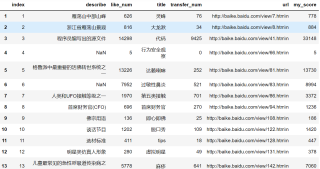
- 请看👉 :pandas中合并数据集