python&requests.get实际应用中的问题
问题遇到的现象和发生背景
import requests
url1 = 'https://www.runoob.com/wp-content/themes/runoob/option/alisearch/v330/hot_hint.php?type=hint&user_id=f3530de6-f57e-4400-b1fb-48240dd1bb9f'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'referer': 'https://www.runoob.com/xpath/xpath-syntax.html'
}
##################################################################################
res1 = requests.get(url1,headers=headers)
print(res1.json())
#...打印结果是[{'hint': 'indexof', 'pv': 94}]
##################################################################################
url2 = 'https://www.runoob.com/wp-content/themes/runoob/option/alisearch/v330/hot_hint.php?'
params = {
'type':' hint',
'user_id':'f3530de6-f57e-4400-b1fb-48240dd1bb9f',
}
res2 = requests.get(url2,params=params,headers=headers)
print(res2.json())
#...打印结果是None
为啥第一种方式能得到请求网址的响应代码,但是第二种方式就得不到结果呢?
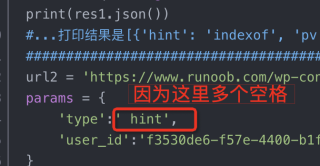
你第二种方式 type 的值多个一个空格
params = {
'type':'hint', # 'hint' 前边多了一个空格
'user_id':'f3530de6-f57e-4400-b1fb-48240dd1bb9f',
}
谷歌浏览器复制参数的时候是
type: hint
user_id: f3530de6-f57e-4400-b1fb-48240dd1bb9f
然后用正则(.*?):(.*)替换成'$1':'$2'时候
踩得坑 应该用正则:(.*?): (.*)替换成'$1':'$2'
这样就能解决这个坑啦!~