list.append() 只接受一个参数(给定 5 个)
import requests
import csv
from lxml import etree
import pandas as pd
page=54
for i in range(page):
url='https://nj.lianjia.com/ershoufang/pg'+str(i)
response=requests.get(url)
data=etree.HTML(response.text)
div_list=data.xpath('//div[@class="info clear"]')
result=[]
for div in div_list:
title=div.xpath('.//div[@class="title"]/a/text()')[0] #爬取标题的信息
positionInfo=div.xpath('.//div[@class="flood"]/div/a[2]/text()')[0]
houseInfo=div.xpath('.//div[@class="address"]/div/text()')[0]
priceInfo=div.xpath('.//div[@class="priceInfo"]/div[1]/span/text()')[0]
tag1=div.xpath('.//div[@class="priceInfo"]/div[2]/span/text()')[0]
result.append(title,positionInfo,houseInfo,priceInfo,tag1)
name= ["名称", "位置信息", "房源信息", "价格信息(万/套)", "标签"]
data=pd.DataFrame(columns=name,data=result)
print(data)
data.to_csv("南京二手房.csv")
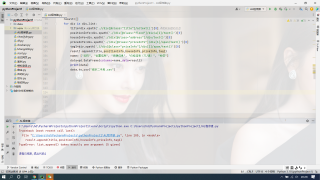
那就再加一个括号呗
result.append((title, positionInfo, houseInfo, priceInfo, tag1))
list的add只能接受一个变量,你是add一个数组进去
result.append([title,positionInfo,houseInfo,priceInfo,tag1])