使用hdfs上传文件报错org.apache.hadoop.hdfs.CannotObtainBlockLengthExceptio
问题遇到的现象和发生背景
使用hdfs上传文件报错,如果是空文件上传就会成功,如果是有内容的文件就会上传失败
运行结果及报错内容
org.apache.hadoop.hdfs.CannotObtainBlockLengthException: Cannot obtain block length for LocatedBlock{BP-293563276-192.168.0.11-1634095772355:blk_1073784416_43592; getBlockSize()=0; corrupt=false; offset=0; locs=[DatanodeInfoWithStorage[192.168.0.11:9866,DS-0f59c3c4-7aae-4baa-b7df-786930725c03,DISK]]}
at org.apache.hadoop.hdfs.DFSInputStream.readBlockLength(DFSInputStream.java:363) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DFSInputStream.fetchLocatedBlocksAndGetLastBlockLength(DFSInputStream.java:270) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DFSInputStream.openInfo(DFSInputStream.java:201) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DFSInputStream.(DFSInputStream.java:185) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DFSClient.openInternal(DFSClient.java:1048) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:1011) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DistributedFileSystem$4.doCall(DistributedFileSystem.java:319) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DistributedFileSystem$4.doCall(DistributedFileSystem.java:315) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) ~[hadoop-common-3.2.1.jar!/:?]
at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:327) ~[hadoop-hdfs-client-3.2.1.jar!/:?]
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:899) ~[hadoop-common-3.2.1.jar!/:?]
at com.jf.common.oss.service.impl.HdfsOSSImpl.getObject(HdfsOSSImpl.java:68) [jfcommon-oss-2.1.0.jar!/:?]
at com.jf.common.oss.JfOSSClient.getObject(JfOSSClient.java:90) [jfcommon-oss-2.1.0.jar!/:?]
at com.jfh.oss.OSSClientProxy.getOSSObject(OSSClientProxy.java:98) [classes!/:?]
at com.jfh.util.MergePartHelper.mergePartFile(MergePartHelper.java:78) [classes!/:?]
at com.jfh.helper.ViewFileHelper.mergePartFile(ViewFileHelper.java:125) [classes!/:?]
at com.jfh.controller.JFZGFileController.mergePartFile(JFZGFileController.java:99) [classes!/:?]
at com.jfh.controller.JFZGFileController$$FastClassBySpringCGLIB$$2bf96aa4.invoke() [classes!/:?]
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218) [spring-core-5.1.15.RELEASE.jar!/:5.1.15.RELEASE]
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:752) [spring-aop-5.1.15.RELEASE.jar!/:5.1.15.RELEASE]
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163) [spring-aop-5.1.15.RELEASE.jar!/:5.1.15.RELEASE]
我的解答思路和尝试过的方法
使用 hdfs fsck -openforwrite这个命令得到的数据中没有openforwrite
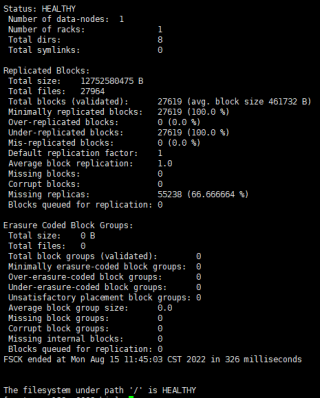
信息不足不是很好判断,找了下源码,报错的方法如下:
/** Read the block length from one of the datanodes. */
private long readBlockLength(LocatedBlock locatedblock) throws IOException {
assert locatedblock != null : "LocatedBlock cannot be null";
int replicaNotFoundCount = locatedblock.getLocations().length;
final DfsClientConf conf = dfsClient.getConf();
final int timeout = conf.getSocketTimeout();
LinkedList<DatanodeInfo> nodeList = new LinkedList<DatanodeInfo>(
Arrays.asList(locatedblock.getLocations()));
LinkedList<DatanodeInfo> retryList = new LinkedList<DatanodeInfo>();
boolean isRetry = false;
StopWatch sw = new StopWatch();
while (nodeList.size() > 0) {
DatanodeInfo datanode = nodeList.pop();
ClientDatanodeProtocol cdp = null;
try {
cdp = DFSUtilClient.createClientDatanodeProtocolProxy(datanode,
dfsClient.getConfiguration(), timeout,
conf.isConnectToDnViaHostname(), locatedblock);
final long n = cdp.getReplicaVisibleLength(locatedblock.getBlock());
if (n >= 0) {
return n;
}
} catch (IOException ioe) {
checkInterrupted(ioe);
if (ioe instanceof RemoteException) {
if (((RemoteException) ioe).unwrapRemoteException() instanceof
ReplicaNotFoundException) {
// replica is not on the DN. We will treat it as 0 length
// if no one actually has a replica.
replicaNotFoundCount--;
} else if (((RemoteException) ioe).unwrapRemoteException() instanceof
RetriableException) {
// add to the list to be retried if necessary.
retryList.add(datanode);
}
}
DFSClient.LOG.debug("Failed to getReplicaVisibleLength from datanode {}"
+ " for block {}", datanode, locatedblock.getBlock(), ioe);
} finally {
if (cdp != null) {
RPC.stopProxy(cdp);
}
}
// Ran out of nodes, but there are retriable nodes.
if (nodeList.size() == 0 && retryList.size() > 0) {
nodeList.addAll(retryList);
retryList.clear();
isRetry = true;
}
if (isRetry) {
// start the stop watch if not already running.
if (!sw.isRunning()) {
sw.start();
}
try {
Thread.sleep(500); // delay between retries.
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new InterruptedIOException(
"Interrupted while getting the length.");
}
}
// see if we ran out of retry time
if (sw.isRunning() && sw.now(TimeUnit.MILLISECONDS) > timeout) {
break;
}
}
// Namenode told us about these locations, but none know about the replica
// means that we hit the race between pipeline creation start and end.
// we require all 3 because some other exception could have happened
// on a DN that has it. we want to report that error
if (replicaNotFoundCount == 0) {
return 0;
}
throw new CannotObtainBlockLengthException(locatedblock);
}
从报错的代码中,只有两个地方能够返回,此处没有返回而抛了这个异常。而没有返回的原因是获取备份的可见长度n<0。代码如下:
final long n = cdp.getReplicaVisibleLength(locatedblock.getBlock());
if (n >= 0) {
return n;
}
数据备份一般与存储有关,注意到你截图上面集群只有一个数据节点。不知道是不是该数据节点的存储已经用光了,可以检查了看看。
信息不足,只能猜测到这些了。
重新安装一次吧
看看这边呢
https://www.cnblogs.com/cssdongl/p/6700512.html
如果没有特别重要得数据,重新装也方便,我之前有写过,从Hadoop到spark 到flink都有得,可以借鉴下
这篇文章讲的很详细,请看:Hadoop上传文件到hdfs报错:org.apache.hadoop.ipc.RemoteException(java.io.IOException)