f.write(book_content.text)报错
我这几行代码哪里错了, f.write(book_content.text)一直在报错
with open('./book/' + book_titil + '.text' , 'a' , encoding='utf-8') as f:
f.write(book_content.text)
print('下载成功',book_titil)
可能是目标网页内容错误,导致语句“book_content = soup.find('div',id='content')”没有获取到id='content'的div标签。(报错简析见文末)
这类错误非常常见(尤其是一些运维不认真、运行得不到高标准保障的小说网站),其实就是目标网页内容一片空白,或者是网页上只有报错信息,这都属于网站没有正确将数据分配到子网页上,不用太担心,只要在代码里添加try结构去捕获异常、跳过空白网页就行了。
像这样:
def get_book(url):
error_links=[]
......
for book_info in book_data:
try:
......
except AttributeError:
error_links.append(book_url)
当然,也可以像上例所示的那样添加error_links列表,获取引发报错的网页地址,核实缺失的信息,再通过其他渠道获取缺失的小说内容。
注意:一定要把try塞到for循环里去,否则程序运行一半就崩了。还有,要先保证没有其他因素引发AttributeError(如语法不规范),否则会有异常的错误捕获来误导。
简析报错信息:
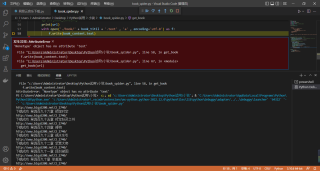
AttributeError: 'NoneType' object has no attribute 'text"
File "C: \Users (Administrator(Desktop(PythoniRV\book_spider.py", line 58, in get_book
f.write(book_content. text)
File "C: \Users (Administrator(Desktop(PythoniRV小\book_spider.py", line 67, in <module>
get_book(url)
这个报错信息意味着自定义函数get_book(url)中的book_content变量没有获取到本次的值,只不过被本次的初始化操作清空了上一次的赋值。而这个变量用于储存获取到的目标网页的id="content"的div标签的文字信息,它没有被赋值,就说明目标网页不存在这一标签,或是目标网页这一标签没有文字信息。
说白了,不是目标网页的服务器分配信息的时候出错了,就是目标网址指向了其他的网页。当然,大多数时候是前者。
您可以采用上面代码块里的方式捕获异常网页,再去人工查看网页,应该八九不离十。
把报错的代码复制到记事本发给我看一下
#导包
from cgitb import html
from email import header
from gettext import find
from nturl2path import url2pathname
import os
from urllib import response
from webbrowser import get #自动创建文件夹储存爬取的文件
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.169.400 QQBrowser/11.0.5130.400'
}
#声明一个函数 包含请求网站功能 以及 筛选信息功能 和 保存数据功能
def get_book(url):
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding #在页面中自动识别编码集并通过同一编码集进行编码
#print(response.text)
soup = BeautifulSoup(response.text,'lxml')
book_data = soup.find_all('div',class_='box_con')[1].find_all('a')
#print(book_data)
#在打印完数据之后还包含了前段代码
#通过 for 循环进行二次筛选 留下章节名称 章节链接
for book_info in book_data:
book_titil = book_info.text
book_url = book_info['href']
#print(book_titil, book_url)
html_contents = requests.get(book_url,headers=headers)
html_contents.encoding = html_contents.apparent_encoding
#print(html_contents.text)
soup = BeautifulSoup(html_contents.text,'lxml')
book_content = soup.find('div',id='content')
#print(book_content)
#print(url)
with open('./book/' + book_titil + '.text' , 'a' , encoding='utf-8') as f:
f.write(book_content.text)
print('下载成功',book_titil)
#函数入口
if name == "main":
if not os.path.exists('./book/'):
os.mkdir('./book/')
url = 'http://www.biqu5200.net/2_2740/'
get_book(url)