python爬虫代码运行不报错,但是保存到CSV的数据为空,是哪里出了问题
问题遇到的现象和发生背景
本人学习python爬虫,分页爬取去哪儿网页的数据,使用pandas保存到csv,但csv的数据为空,然后有时候能保存数据,但只能保存一页的数据
问题相关代码,请勿粘贴截图
import time
import json
import random
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
}
def get_city_data(cities, pages):
cityNames = []
sightNames = []
stars = []
scores = []
qunarPrices = []
saleCounts = []
districtses = []
points = []
intros = []
frees = []
addresses = []
for city in cities:
for page in range(1, pages+1):
try:
print(f'正在爬取{city}第{page}页数据...')
time.sleep(random.uniform(1.5, 2.5))
url = f'https://piao.qunar.com/ticket/list.json?keyword={city}®ion=&from=mps_search_suggest&page={page}'
print('url:', url)
respone = requests.get(url, headers=headers, timeout=(2.5, 5.5))
status = respone.status_code
if (status == 200):
# 每页数据
response_info = json.loads(respone.text)
print('数据:', response_info)
sight_list = response_info['data']['sightList']
for sight in sight_list:
sightName = sight['sightName'] # 名称
star = sight.get('star', None) # 星级
score = sight.get('score', 0) # 评分
qunarPrice = sight.get('qunarPrice', 0) # 价格
saleCount = sight.get('saleCount', 0) # 销量
districts = sight.get('districts', None) # 行政区划
point = sight.get('point', None) # 坐标
intro = sight.get('intro', None) # 简介
free = sight.get('free', True) # 是否免费
address = sight.get('address', None) # 地址
cityNames.append(city)
sightNames.append(sightName)
stars.append(star)
scores.append(score)
qunarPrices.append(qunarPrice)
saleCounts.append(saleCount)
districtses.append(districts)
points.append(point)
intros.append(intro)
frees.append(free)
addresses.append(address)
except:
continue
city_dic = {'cityName': cityNames, 'sightName': sightNames, 'star': stars,
'score': scores, 'qunarPrice': qunarPrices, 'saleCount': saleCounts,
'districts': districtses, 'point': points, 'intro': intros,
'free': frees, 'address': addresses}
city_df = pd.DataFrame(city_dic)
city_df.to_csv('cities.csv', index=False)
if __name__ == '__main__':
city_list = ['福建']
pages = 3
get_city_data(city_list, pages)
运行结果及报错内容
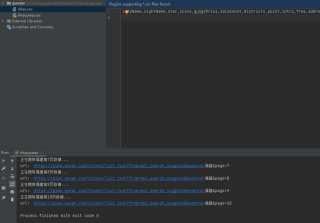
respone.text获取的json数据格式有问题,用 json.loads(respone.text)解析出错
另外写csv文件的代码要放到for循环外面,所有数据获取之后再一起写入
city_dic = {'cityName': cityNames, 'sightName': sightNames, 'star': stars,
'score': scores, 'qunarPrice': qunarPrices, 'saleCount': saleCounts,
'districts': districtses, 'point': points, 'intro': intros,
'free': frees, 'address': addresses}
city_df = pd.DataFrame(city_dic)
city_df.to_csv('cities.csv', index=False)
没获取到数据

你在except哪里也输出一段话,看看是不是出错被捕获了
网站做了反爬,直接用request爬取难度很大,建议使用seleinum动态爬虫试试。
这个url???

import time
import json
import random
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
}
def get_city_data(cities, pages):
cityNames = []
sightNames = []
stars = []
scores = []
qunarPrices = []
saleCounts = []
districtses = []
points = []
intros = []
frees = []
addresses = []
for city in cities:
for page in range(1, pages+1):
try:
print(f'正在爬取{city}第{page}页数据...')
time.sleep(random.uniform(1.5, 2.5))
url = f'https://piao.qunar.com/ticket/list.json?keyword={city}& region=&from=mps_search_suggest&page={page}'
print('url:', url)
result = requests.get(url, headers=headers, timeout=(2.5, 5.5))
status = result.status_code
if (status == 200):
# 每页数据
response_info = json.loads(result.text)
print('数据:', response_info)
sight_list = response_info['data']['sightList']
for sight in sight_list:
sightName = sight['sightName'] # 名称
star = sight.get('star', None) # 星级
score = sight.get('score', 0) # 评分
qunarPrice = sight.get('qunarPrice', 0) # 价格
saleCount = sight.get('saleCount', 0) # 销量
districts = sight.get('districts', None) # 行政区划
point = sight.get('point', None) # 坐标
intro = sight.get('intro', None) # 简介
free = sight.get('free', True) # 是否免费
address = sight.get('address', None) # 地址
cityNames.append(city)
sightNames.append(sightName)
stars.append(star)
scores.append(score)
qunarPrices.append(qunarPrice)
saleCounts.append(saleCount)
districtses.append(districts)
points.append(point)
intros.append(intro)
frees.append(free)
addresses.append(address)
except:
continue
city_dic = {'cityName': cityNames, 'sightName': sightNames, 'star': stars,
'score': scores, 'qunarPrice': qunarPrices, 'saleCount': saleCounts,
'districts': districtses, 'point': points, 'intro': intros,
'free': frees, 'address': addresses}
city_df = pd.DataFrame(city_dic)
city_df.to_csv('cities.csv', index=False)
if __name__ == '__main__':
city_list = ['福建']
pages = 3
get_city_data(city_list, pages)
404啦,反扒太厉害

关注一下