flink如何禁止source并行度大于1
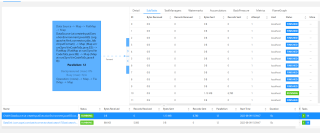
最近写flink遇到个问题,代码逻辑很简单,就是flink从clickhouse读取数据,然后简单转换存入es,但是并行度遇到个问题,我在提交时候指定并行度为12,然后souce端的并行度也成为了12,与后续map等算子直接合并了,就导致source只有一个solt在工作,然后后面的map也只有一个solt,其他的都finish了,如图
如果我手动把source并行度设为1,就需要再手动把map设为12,这样确实可以解决问题,如图
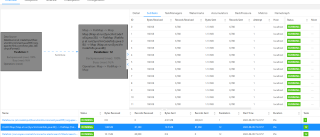
但是这样就导致并行度写死了,以后资源分配调整都挺费劲的,我想知道为什么会这样,还有其他解决办法吗。
附上clickhouse的souce代码
batchEnv.createInput(JdbcInputFormat.buildJdbcInputFormat()
.setDBUrl(String.format("jdbc:clickhouse://%s:%s/%s?%s",
dbConfigProperties.getHost()
, dbConfigProperties.getPort()
, dbConfigProperties.getBDName()
, "socket_timeout=240000000"))
.setDrivername(dbConfigProperties.getDriver())
.setUsername(dbConfigProperties.getUserName())
.setPassword(dbConfigProperties.getPassword())
.setQuery(sql)
.setRowTypeInfo(rowTypeInfo)
.finish()
).setParallelism(1);
```
flink批处理,不是流处理
简单一点你可以使用多个环境变量注入的形式来控制多个算子的并行度