为什么同样的xpath路径 在xpath中和pycharm中显示的内容不一样

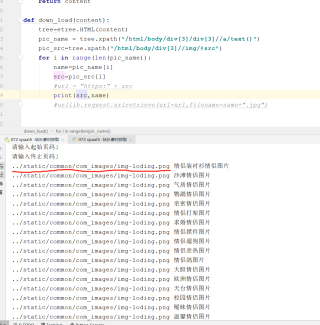
为什么同样的xpath路径 在xpath中和pycharm中显示的内容不一样,pycharm中的这个路径也确实获取不了网页中的内容。
这是网页源码
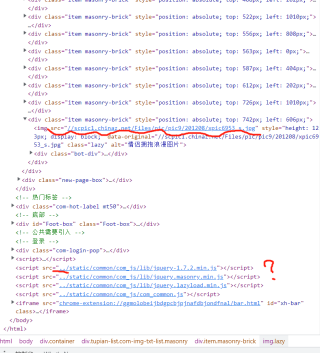
这是全部代码



第二张图明显题主是开发工具审核dom进行查看,这个并不是源代码,审核dom得到的html代码有可能被js修改过,而request之类得到的是源代码
下面这种才叫源代码,src是默认的加载等待图片,实际图片网址存储在data-original属性中,然后通过js来动态加载图片
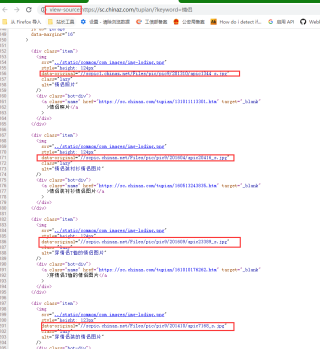
将下面代码的@src改为@data-original
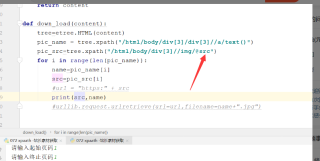
你的xpath没写错,问题在你request获取的网页都还没加载完,有可能该网页是异步加载的,这种情况推荐使用selenium去爬取
你这样去理解。
一个网页是有多个url请求返回的数据组成的。
而你只请求了一个url,你得到的返回值不是整个网页的内容。
你得去打印看看返回的内容中有没有你需要的资源
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632