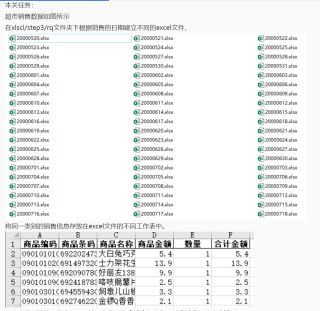
pandas数据处理将超市销售excel文件分别存放在多个日期工作簿的不同类别工作表中
问题遇到的现象和发生背景

问题相关代码,请勿粘贴截图
import pandas as pd
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx",dtype={"商品编码":str,"商品条码":str})
#代码开始
#代码结束
运行结果及报错内容
import pandas as pd
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx",dtype={"商品编码":str,"商品条码":str})
#代码开始
df1=df["日期"].unique()
for i in df1:
i2=pd.to_datetime(i)
i3=i2.strftime('%Y%m%d')
df2=df.loc[df["日期"]==i,["商品编码","商品名称","合计金额","类别"]]
df6=df2["类别"].unique()
writer=pd.ExcelWriter('xlscl/step3/rq/'+i3+'.xlsx')
k=[]
for n in df6:
df8=df2.loc[df2["类别"]==n]
df8.to_excel(writer,sheet_name=n,index=False)
k.append([n,df8['合计金额'].sum()])
df7=pd.DataFrame(k,columns=["类别","合计金额"])
df7.to_excel(writer,sheet_name="类别统计",index=False,header=["类别","合计金额"])
writer.save()
#代码结束
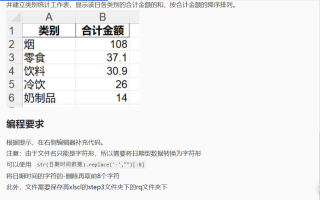
我想要达到的结果
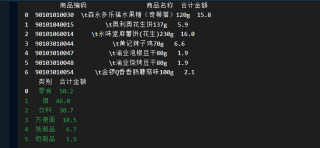
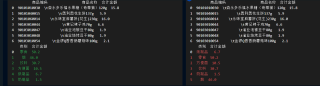
您好 我看您的结果离标准答案就差了排序 所以我的想法是 您应该缺少了对k的排序
import pandas as pd
def f(x):
return x[-1]
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx",dtype={"商品编码":str,"商品条码":str})
#代码开始
df1=df["日期"].unique()
for i in df1:
i2=pd.to_datetime(i)
i3=i2.strftime('%Y%m%d')
df2=df.loc[df["日期"]==i,["商品编码","商品名称","合计金额","类别"]]
df6=df2["类别"].unique()
writer=pd.ExcelWriter('xlscl/step3/rq/'+i3+'.xlsx')
k=[]
for n in df6:
df8=df2.loc[df2["类别"]==n]
df8.to_excel(writer,sheet_name=n,index=False)
k.append([n,df8['合计金额'].sum()])
df7=pd.DataFrame(k.sort(key=f,reverse=True),columns=["类别","合计金额"]) # 将k中元素进行排序 排序参照值key为每一个列表的最后值(金额总和)
df7.to_excel(writer,sheet_name="类别统计",index=False,header=["类别","合计金额"])
writer.save()
可以参考我的博客https://blog.csdn.net/qq_52785473/article/details/122870015里面第20条
分配不规则,形成渲染错误