知乎盐选的代码错误问题
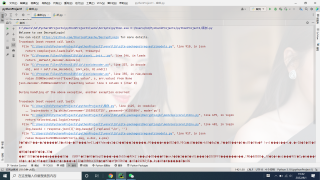
from DecryptLogin import login
from bs4 import BeautifulSoup
import re
import base64
lg = login.Login()
_, loginstauts = lg.zhihu(username='账户名', password='密码', mode='pc')
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
}
url1 = "https://www.zhihu.com/market/paid_column/1178733193687175168/section/1178742737682350080"
url2 = "https://www.zhihu.com/market/paid_column/1178733193687175168/section/1178742849583083520"
# 获取链接
r = loginstauts.get(url1, headers=headers)
wenzi = r.text
soup = BeautifulSoup(wenzi, 'lxml')
lianjie = soup.textarea
lianjie = str(lianjie)
pattern = re.compile('"next_section":{"url":"(.+)","is_end":') #正则匹配链接所在的文字
result = pattern.findall(lianjie)
texts = soup.find_all('p')
for text in texts:
with open("yanxuan.txt", 'a', encoding='utf-8') as file_object:
file_object.write(text.get_text()+" ")
list = result.pop(0)
print(list)
for link in range(0, 9):
r2 = loginstauts.get(list, headers=headers)
wenzi = r2.text
soup = BeautifulSoup(wenzi, 'lxml')
lianjie = soup.textarea
lianjie = str(lianjie)
pattern = re.compile('"next_section":{"url":"(.+)","is_end":') # 正则匹配链接所在的文字
result = pattern.findall(lianjie)
list = result.pop(0)
texts = soup.find_all('p')
for text in texts:
with open("yanxuan.txt", 'a', encoding='utf-8') as file_object:
file_object.write(text.get_text()+" ")
已经输入密码登录过
这好像是解码错误,,好像目录内部里面的代码块,怎么调试啊,
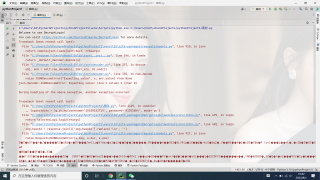
你这截图怎么是马赛克