之前运行好多遍都是好的,怎么突然报错了呢?
import urllib.request
from lxml import etree
import requests
def create_request(page):
if(page == 1):
url = 'https://www.cgtrader.com/3d-models?free=1&page=1'
else:
url = 'https://www.cgtrader.com/free-3d-models?keywords=' + str(page) +'.html'
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
request = urllib.request.Request(url = url, headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
#urllib.request.urlretrieve('模型地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//*[@id="fast-list-container"]//img/@src')
src_list = tree.xpath('//*[@id="fast-list-container"]//img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url ='https:' + src
urllib.request.urlretrieve(url=url,filename='./moximg/'+name + '.jpg')
if name == 'main':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
(1)请求对象的定制
request = create_request(page)
(2)获取网页源码
content = get_content(request)
(3)下载
down_load(content)
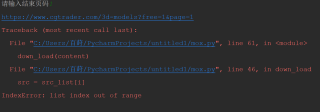
IndexError:列表索引超出了范围

原因:list在读取的时候下标是从0开始读取的,list在已经定义的范围内,我们可以读取到索引值对应的值,但是如果下标没有定义,那么他的值是没有办法读取到的,这个时候也就是为社么会出现
IndexError: list index out of range。解决方案:
1、try ...except ...continue...
2、根本解决:查看报错行数,找到出错的list,输出长度,如果有不同的list,分别输出一下list的长度
一步步定位,首先看看是不是爬虫失效了,有没有正常爬取到网页源码。如果正常爬取到源代码,查查看Xpath路劲是否依旧有效,网页源代码的Xpath路劲有没有变化。一般爬虫失效,可能的问题是,①遇到反爬机制,需要想办法绕过。②网页元素变更,需要重新进行元素定位。慢慢调试一下吧。