txt文件提取数据到excle文件
txt文件提取数据到excle文件,输出到excle文档操作不熟悉
TXT部分文档:
07-18_12.17.01.550[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.01.550[localplayer][D][14866][PlayerStatHelper.cpp(092)]:ABR setAbrs idx:0 bitrate:379203 bwe:8629337 buffer:9951 switchBr:0
07-18_12.17.01.550[localplayer][D][14866][Controller.cpp(741)]:get next level 0
07-18_12.17.02.056[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.02.056[localplayer][D][14866][StatHelper.cpp(092)]:ABR setAbrs idx:4 bitrate:1422296 bwe:8770076 buffer:21424 switchBr:0
07-18_12.17.02.056[localplayer][D][14866][Controller.cpp(741)]:get next level 4
07-18_12.17.02.056[localplayer][D][14866][Controller.cpp(1900)]:actual pause download
07-18_12.17.13.887[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.13.887[localplayer][D][14866][StatHelper.cpp(092)]:ABR setAbrs idx:4 bitrate:1422296 bwe:9168943 buffer:22838 switchBr:0
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(741)]:get next level 4
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(1900)]:actual pause download
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(1291)]:HlsPlayManager stat change 4->5
从Txt文档中提取对应字段的数据,需要采集的数据大多都是这三行的形式,字段一致,数据不同



需要的结果
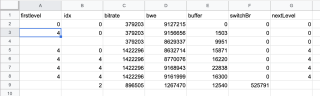
问题相关代码,请勿粘贴截图
```python
fi = open("yylocalplayer_jni_2022_07_27_16_48_39_1.txt","r",encoding="utf-8")
line = fi.readlines() #整个文件读入
key_word = "Asbrs "
datas = line.split(key_word)[1] #按指定单词分割
items=datas.split(' ')
kvs={}
for item in items:
if len(item.split(':')) == 2:
k = item.split(':')[0]
v = item.split(':')[1]
kvs[k] = v
fi.close()
import pandas as pd
s='''07-18_12.17.01.550[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.01.550[localplayer][D][14866][PlayerStatHelper.cpp(092)]:ABR setAbrs idx:0 bitrate:379203 bwe:8629337 buffer:9951 switchBr:0
07-18_12.17.01.550[localplayer][D][14866][Controller.cpp(741)]:get next level 0
07-18_12.17.02.056[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.02.056[localplayer][D][14866][StatHelper.cpp(092)]:ABR setAbrs idx:4 bitrate:1422296 bwe:8770076 buffer:21424 switchBr:0
07-18_12.17.02.056[localplayer][D][14866][Controller.cpp(741)]:get next level 4
07-18_12.17.02.056[localplayer][D][14866][Controller.cpp(1900)]:actual pause download
07-18_12.17.13.887[localplayer][D][14866][face.cc(100)]:ABR Get Next Level: 4
07-18_12.17.13.887[localplayer][D][14866][StatHelper.cpp(092)]:ABR setAbrs idx:4 bitrate:1422296 bwe:9168943 buffer:22838 switchBr:0
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(741)]:get next level 4
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(1900)]:actual pause download
07-18_12.17.13.887[localplayer][D][14866][Controller.cpp(1291)]:HlsPlayManager stat change 4->5'''
df = pd.DataFrame(columns=['firstlevel', 'idx', 'bitrate', 'bwe', 'buffer', 'switchBar', 'nextLevel'])
find_lines = re.findall('Get Next Level.*?idx:.*?get next level.*?\n', s, flags=re.DOTALL)
for i in find_lines:
list_value = re.findall(r':\s{0,1}(\d+)', i)
list_value.extend(re.search('get next level (\d+)', i)[1])
df.loc[len(df)] = list_value
df.to_excel('result.xlsx', index=False)
您实际代码可用下面的,把filename替换文件对应的路径即可:
import re
import pandas as pd
with open('filename', 'r') as f:
s = f.read()
df = pd.DataFrame(columns=['firstlevel', 'idx', 'bitrate', 'bwe', 'buffer', 'switchBar', 'nextLevel'])
find_lines = re.findall('Get Next Level.*?idx:.*?get next level.*?\n', s, flags=re.DOTALL)
for i in find_lines:
list_value = re.findall(r':\s{0,1}(\d+)', i)
list_value.extend(re.search('get next level (\d+)', i)[1])
df.loc[len(df)] = list_value
df.to_excel('result.xlsx', index=False)
解决方法
没看到你的输入文件是什么,写一个简单点的方法思路
简单点的方法,直接输出成 .csv文件,可以用excel打开。
output_file = "output.csv"
temp_str1 = "4 4 1422296 8632714 15871 1043093 4"
temp_str2 = "0 0 379203 8793003 4931 0 4"
with open(output_file, "w") as fw:
fw.write("firstlevel,idx,bitrate,bwe,buffer,switchBr,nextLevel" + '\n')
# 下面两句只是示范,将每个字段用`,`隔开写入".csv"文件即可
fw.write(temp_str1.replace(" ", ",") + '\n')
fw.write(temp_str2.replace(" ", ",") + '\n')
输出为: output.csv,excel打开即可
firstlevel,idx,bitrate,bwe,buffer,switchBr,nextLevel
4,4,1422296,8632714,15871,1043093,4
0,0,379203,8793003,4931,0,4
如果觉得不想这样输出为.csv的话,就用pandas 处理下 转换为xlsx文件,或者直接用pandas处理存储为xlsx文件都行
如有问题及时沟通
注意分隔符
表格可以用csv文件来代替,因为CSV比较特殊。直接写入一个CSV文件应该就有Excle表格的效果了
可以用openpyxl,个人感觉这个用来读写excel还是比较方便的,你把txt文件给我,我可以帮你写
你前面如果可以得出列表
[firstlevel, idx, bitrate, bwe, buffer, switchBr, nextLevel]
[4, 4, 1422296, 8632714, 15871, 1043093, 4]
[0, 0, 379203, 8793003, 4931, 0, 4]
那么放进excel只要
import openpyxl
wb = openpyxl.load_workbook('./OpenPyXl_test/未命名.xlsx')
sheet = wb.active
sheet.append([firstlevel, idx, bitrate, bwe, buffer, switchBr, nextLevel])
sheet.append([4, 4, 1422296, 8632714, 15871, 1043093, 4])
sheet.append([0, 0, 379203, 8793003, 4931, 0, 4])
wb.save('./OpenPyXl_test/未命名.xlsx')
可以先通过流读进来,转换成对象,然后通过easyexcel直接模板导出,十分简单。
这是我写的关于easyexecel使用方式。
就是一个简单的TXT日志文档,提取对应字段的数据保存为表格就行,如截图所示