关于dataframe报错!这个报错怎么解决呢?
这个是想在Tokenizer的帮助下对文本的所有单词进行标记。大家帮忙看看一下,这个报错应该怎么解决呢?
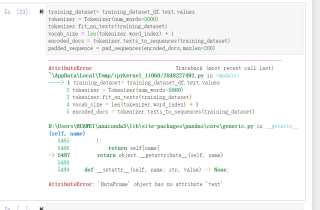
你这是在干嘛呢?删除.text
从代码的提示中看,是对象training_dataset_df没有text属性,请检查一下df.keys(),或者尝试改用training_dataset_df[‘text’].values
这个是想在Tokenizer的帮助下对文本的所有单词进行标记。大家帮忙看看一下,这个报错应该怎么解决呢?
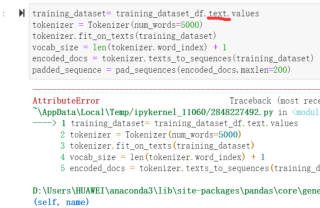
你这是在干嘛呢?删除.text
从代码的提示中看,是对象training_dataset_df没有text属性,请检查一下df.keys(),或者尝试改用training_dataset_df[‘text’].values