embedding 矩阵是根据什么来生成的呢
在学习Word2Vec的时候
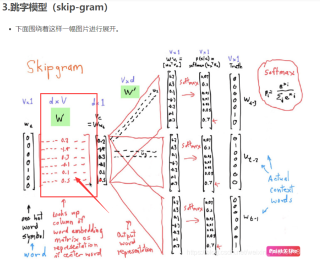
会使用到一层embedding 层来使中心词的ont-hot 矩阵降维,但是我想知道 这个embedding layer里面的这个embedding 矩阵是根据什么来生成的呢? 有什么论文或者谁能解释一下原理么?
这个问题我以前也困扰过,研究半天发现结果其实特别简单,embedding 层就是一个查找表。这就是说,如果你有 10 个 token,也就是有 10 种 one-hot 编码,那么每一个 one-hot 都对应一个 embedding 结果,给他全部记录下来就好,之后靠着 BP 算法,能自动把这些 embedding 学习到。
对应到 pytorch 的源码,更是简单,对应源码 https://github.com/pytorch/pytorch/blob/5b03ff0a09d43d721067e39da10aa23edc6997cd/aten/src/ATen/native/Embedding.cpp#L14-L29 中 14~29 行,你会发现他就一个 index_select 函数,说明 embedding 里面的矩阵就是一个查找表,根本连乘法运算都没有:
Tensor embedding(const Tensor & weight, const Tensor & indices,
int64_t padding_idx, bool scale_grad_by_freq, bool sparse) {
auto indices_arg = TensorArg(indices, "indices", 1);
checkScalarType("embedding", indices_arg, kLong);
// TODO: use tensor.index() after improving perf
if (indices.dim() == 1) {
return weight.index_select(0, indices);
}
auto size = indices.sizes().vec();
for (auto d : weight.sizes().slice(1)) {
size.push_back(d);
}
return weight.index_select(0, indices.reshape(-1)).view(size);
}