爬取的信息保存到csv文件里
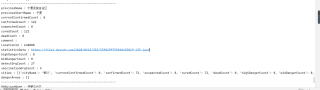
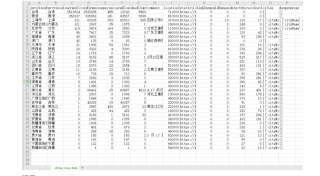
爬取全国各省的疫情信息然后保存到csv文件里面,跟这样示意的图片一样,怎么保存啊,搞了一晚上还是不会搞,有谁会的吗
from bs4 import BeautifulSoup
import requests
import re
import json
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia')
res = response.content.decode()
soup = BeautifulSoup(res, 'lxml')
script = soup.find(id="getAreaStat")
text = script.text
zfc = re.findall(r'\[.+\]', text)[0]
rs = json.loads(zfc)
fields = ['provinceName', 'provinceShortName', 'currentConfirmedCount', 'confirmedCount',
'suspectedCount', 'curedCount', 'deadCount', 'comment', 'locationId', 'statisticsData', 'highDangerCount', 'midDangerCount', 'detectOrgCount', 'vaccinationOrgCount', 'cities', 'dangerAreas']
with open('abc.csv', 'w', encoding='UTF-8') as fp:
fp.write(','.join(fields)) # 写入表头行
fp.write('\n') # 写入换行符
for di in rs: # 对每一行遍历
l = list(di.values()) # 将当前行的值转换成列表
s = ""
for i in range(len(l)-1):
# 将当前行的值拼接成字符串,每个值两侧加双引号去处理内容中的逗号;值之间用逗号分隔
s += "\""+str(l[i])+"\""+","
s += "\""+str(l[len(l)-1])+"\""
fp.write(s) # 写入行
fp.write('\n') # 写入换行符
fp.close()
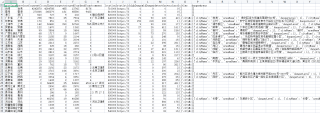
大致应该如下这个框架:
fp = open('yigjhxxio0o9.csv','a')
fp.write(','.join(fieldnames))
for di in rs:
fp.write(','.join(di.values())
fp.close()
保存数据,就可以用python的方法。这个和爬虫没关系。你可以百度搜Python保存csv