如何用SELENIUM连接接管已经手动打开的IE浏览器
如题。
注意:
- IE浏览器(回答Chrome浏览器的不会采纳)
- 已经手动打开的IE浏览器(是手动打开的浏览器!回答其他方式打开浏览器的,不会采纳)
- 此需求为单位内网环境,不能其他安装软件,Python和各类包(包括SELENIUM环境)可以使用。
本人非IT专业,PYTHON自学2年 。
求高人指导可行的、简便的连接方案。
from typing import NoReturn
from selenium.webdriver import Ie
def catch_ie(attach_url: str) -> NoReturn:
"""
捕获已打开IE
:param attach_url: 手动打开IE的url
"""
# 启动IE
driver = Ie()
# 执行命令
driver.command_executor._commands["attachToBrowser"] = ("POST", '/session/$sessionId/attach')
hw = driver.execute("attachToBrowser", {"url": attach_url})
# 关闭driver启动的浏览器
driver.close()
# 切换
driver.switch_to.window(hw["value"])
# 打印title,如果title为"百度一下"则成功
print(driver.title)
# 手动打开IE浏览器,访问百度
catch_ie(attach_url="https://www.baidu.com/")
可以使用watir-webdriver
Watir跟Selenium都是用来定位web元素,它是一种基于网页模式的自动化功能测试工具。
对ie支持性能突出。
require 'watir-webdriver'
def attach_browser(browser, how, url)
browser.driver.switch_to.window(browser.driver.window_handles[0])
browser.window(how, /#{url}/).use
end
ie2 = Watir::Browser.new :chrome
ie2.goto("http://www.baidu.com/more/")
ie2.link(:text, "网页").click
#p ie2.windows(:url, "http://www.baidu.com/")[-1]
ie3 = ie2.driver.switch_to.window("http://www.baidu.com/")
puts ie3.links

我遇到过和你一样的需求,内网而且有些资源只能ie才能访问,比你的还复杂一点是证书登陆有些资源还需要activex控件才能访问,下面几个办法我都试过了。
- selenium IE打开登录界面,sleep一段时间,在这期间登陆成功就可以继续操作了。
- 获取IE cookies,然后selenium使用cookies登陆,这时就算用chrome也几乎可以访问所有资源。
- 用360极速浏览器这一类两种内核的浏览器切换到兼容模式,然后剩下的操作和chrome是一毛一样的。
- 直接用requests发送post请求就好了,和什么浏览器无关。
我最后用第4种办法,内网也没有反爬加上多线程效率不是一般的高也省去很多浏览器控制的操作。
建议在外网安装Anaconda,然后整个文件夹拷贝到内网再配置下环境变量就能直接用了,添加模块也只需要拷贝相应的文件夹就好了。
另外如果你会c#也可以用winform的webbrowser控件来操作。
那就试试这个https://blog.csdn.net/chuhe163/article/details/108422628
话说为什么一定要手动打开在接管
效果图示:
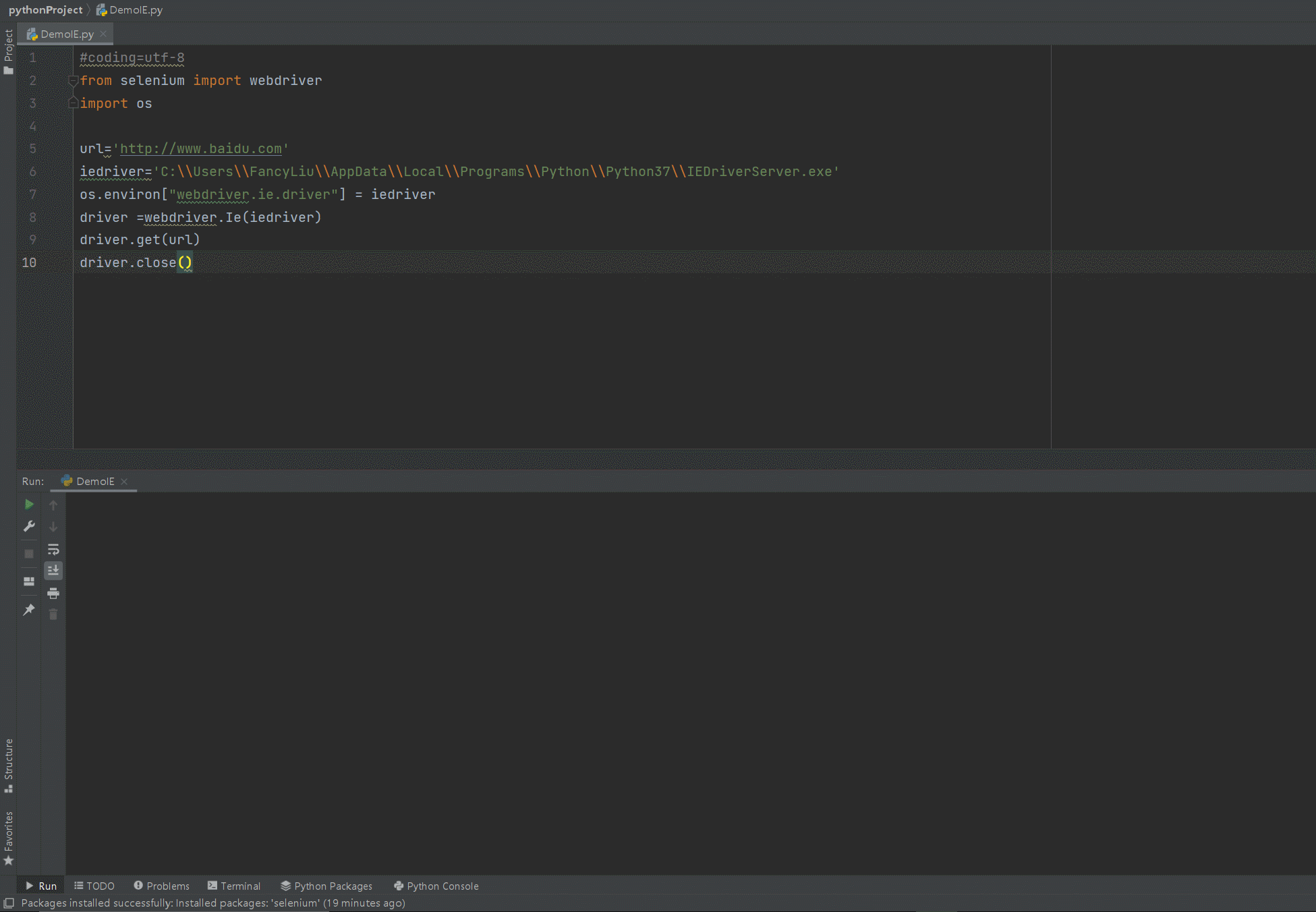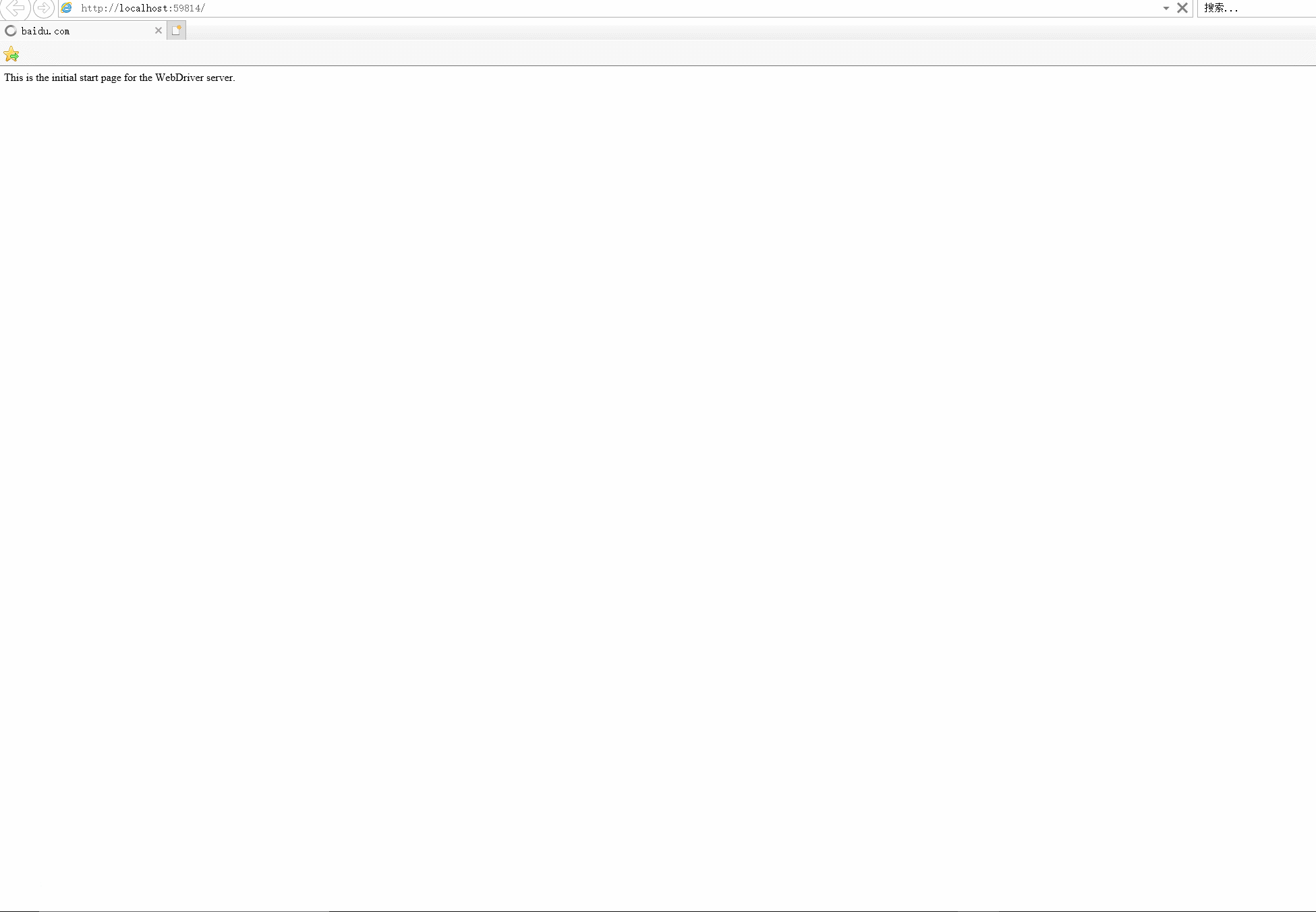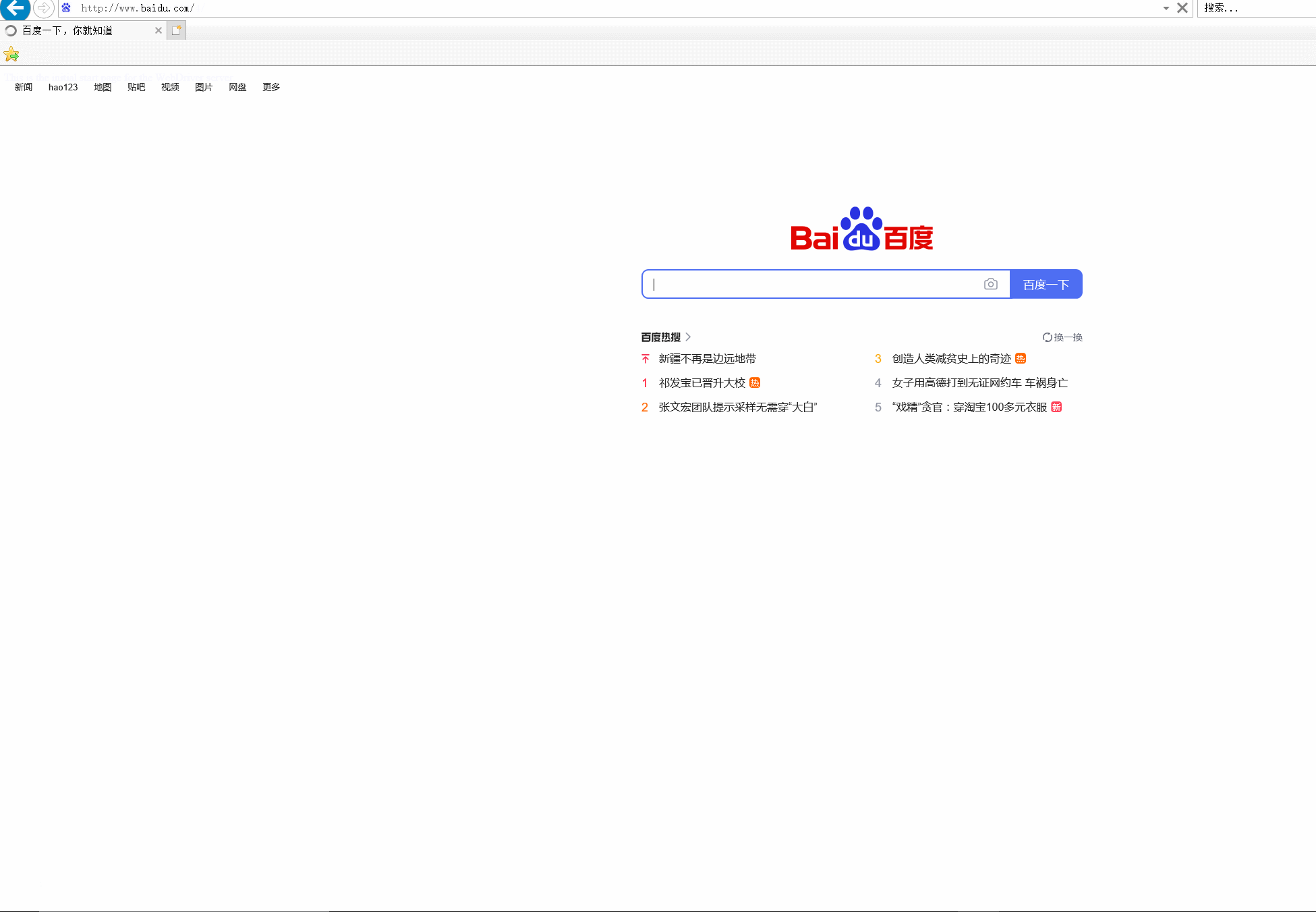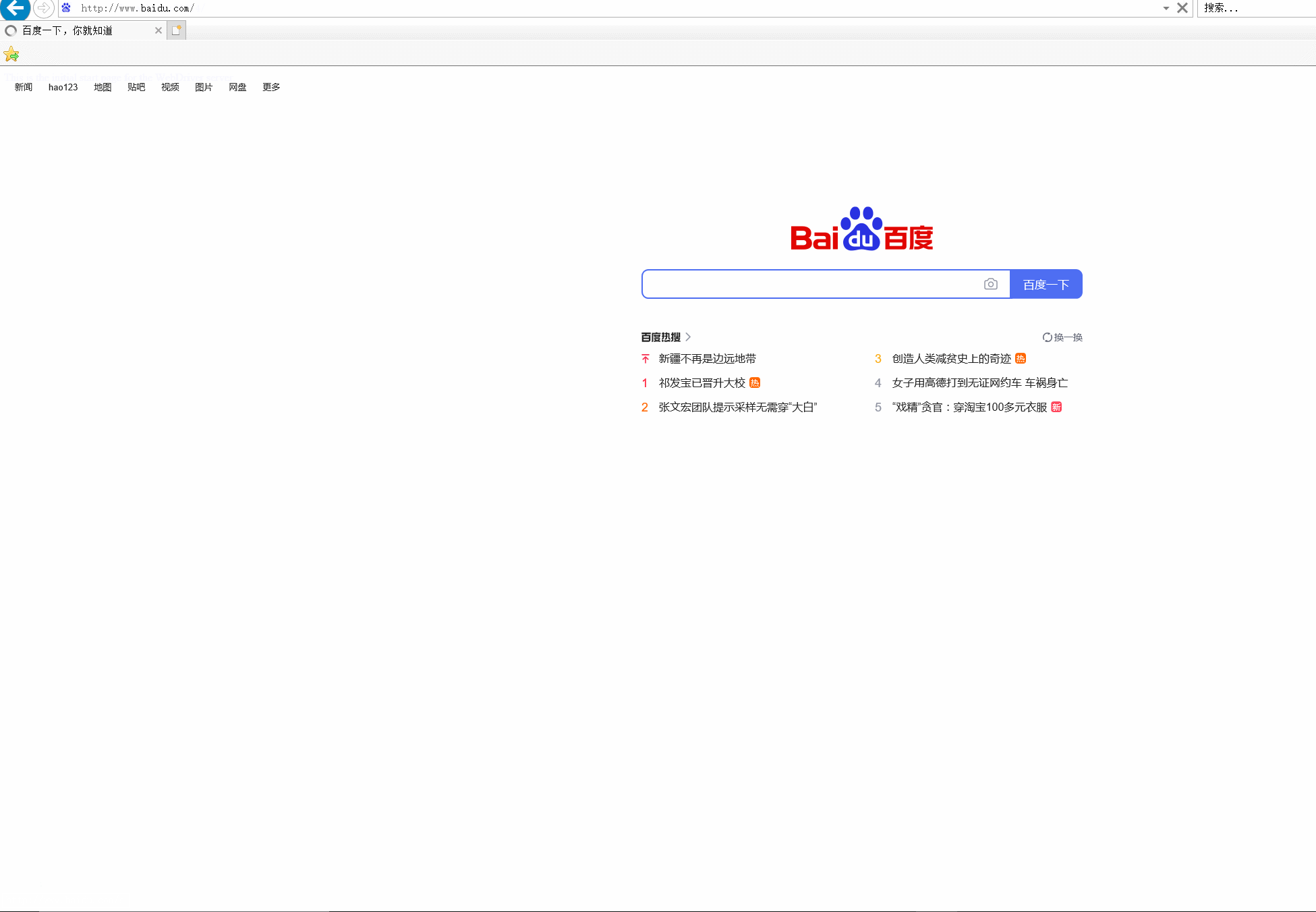
为了抓取浏览器,需要安装其相应的驱动程序,IE驱动程序下载详情页:
https://www.selenium.dev/documentation/ie_driver_server/
下载地址:https://www.selenium.dev/downloads/
下载后驱动,复制到本地python的安装目录,如下代码位置的 iedriver='IEDriverServer.exe的安装路径'
#coding=utf-8 # 编码统一为UTF-8
from selenium import webdriver # 导入selenium的webdriver包
import os
url='http://www.baidu.com'
iedriver='C:\\Users\\AppData\\Local\\Programs\\Python\\Python37\\IEDriverServer.exe' # IEDriverServer.exe的路径
os.environ["webdriver.ie.driver"] = iedriver # 设置IEDriver的环境变量
driver =webdriver.Ie(iedriver) # webdriver的Ie赋值给driver
driver.get(url)
driver.close()
IE浏览器的版本对不?
按以前的思路,可以写个BHO插件(现在的IE或叫Edge,是以Chrome为核心,也可以写扩展,但远不如BHO权力大),BHO基本算嵌入IE的Spy,可以任意控制IE的细节,包括访问什么内容,哪些显示哪些不显示。
注册完BHO,余下的就好办多了,通过socket、进程间通信(简单的处理,如通过互斥量、关键区等传触发信号),感觉socket更简单,而且可以自定义更多的命令。
可以看看这两篇文章:使用python+selenium控制手工已打开的浏览器 - 重案组之虎曹达华 - 博客园
如何突破网站对Selenium的屏蔽(1)接管手动打开的Chrome浏览器_木鱼与琴的博客-CSDN博客
第一步:新建一个映射,以保存原来的chrome不被污染
添加环境变量
将chrome.exe放入系统环境变量中,找到驱动位置添加变量
新建一个存放新环境的文件夹并映射
使用指令【chrome.exe --remote-debugging-port=9222 --user-data-dir="E:\data_info\selenium_data"】
其中--remote-debugging-port是建立新的移植位置,其中端口后面会使用(自定义), --user-data-dir是数据存储的目录(自定义)
此时会打开一个网页放着就行
第二步:selenium代码接管
import time
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
class ZhiHu:
def __init__(self):
self.url = 'https://www.zhihu.com/'
self.chrome_options = Options()
self.chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
self.browser = webdriver.Chrome(executable_path=r'E:\Environment\python_global\Scripts\chromedriver.exe', options=self.chrome_options) # executable执行webdriver驱动的文件
def get_start(self):
self.browser.get(self.url)
# time.sleep(20) # 可以选择手动登录或者是自动化,我这里登录过就直接登陆了
info = self.browser.get_cookies() # 获取cookies
print(info)
with open(r"..\download_txt\info.json", 'w', encoding='utf-8') as f:
f.write(json.dumps(info))
if __name__ == '__main__':
zhihu = ZhiHu()
zhihu.get_start()
IE浏览器不支持操作。升级一下IE浏览器。建一个映射。安装一个IE插件。希望能帮到你!
可以看看这个 https://zhuanlan.zhihu.com/p/108925650
我猜测你是因为需要登录之类的才需要先打开网页,然后在做后续处理。
如果是这样的话 ,按如下位置操作,可以不适用cooks。
1、在代码中相应登录位置打断点;
2、手动进行登录验证;
3、按f9继续执行代码,完成后续工作。
ie已经不维护了,不过可以试一下selenium插件
selenium 要跟 浏览器版对应,你内置的也没法知道浏览器版本把
 http://t.zoukankan.com/lovealways-p-9813059.html
http://t.zoukankan.com/lovealways-p-9813059.htmlfrom typing import NoReturn
from selenium.webdriver import Ie
def catch_ie(attach_url: str) -> NoReturn:
"""
捕获已打开IE
:param attach_url: 手动打开IE的url
"""
driver = Ie()
driver.command_executor._commands["attachToBrowser"] = ("POST", '/session/$sessionId/attach')
hw = driver.execute("attachToBrowser", {"url": attach_url})
driver.clos
driver.switch_to.window(hw["value"])
print(driver.title)
catch_ie(attach_url="https://www.baidu.com/")
官方宣布的:IE 11 已于 2022 年 6 月 15 日停用 如有任何网站需要使用 Internet Explorer (IE) 才能访问,请使用更快、更现代化的 Microsoft Edge 浏览器中的 IE 模式。