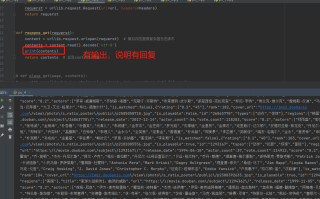
基础爬虫 不报错也不下数据
import urllib.parse
import urllib.request
def requert_get(page):
first_url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20, #根据上面规则start = (page-)*20. 所以我们需要实参page的值
'limit':20
}
data=urllib.parse.urlencode(data)
url= first_url+data
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
requerst=urllib.request.Request(url=url,headers=headers)
return requerst
def reqopne_get(requerst):
content = urllib.request.urlopen(requerst) #模拟浏览器像服务器发送请求
contents=content.read().decode('utf-8')
return contents #返回contents的值
def plase_get(page,contents):
with open('douban.'+str(page)+'json','w',encodings='utf-8') as fp:
fp.write(contents)
if __name__ == '__main__':
utf_name=int(input('请输入开始页码'))
last_name=int(input('请输入结束页码'))
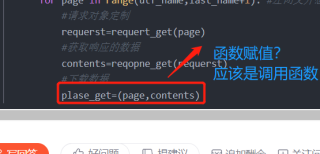
for page in range(utf_name,last_name+1): #左闭又开想要获取10页数据 10+1 11获取第10页数据
#请求对象定制
requerst=requert_get(page)
#获取响应的数据
contents=reqopne_get(requerst)
#下载数据
plase_get=(page,contents)
帮你改好了
```python
import urllib.parse
import urllib.request
def requert_get(page):
first_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start': (page - 1) * 20, # 根据上面规则start = (page-)*20. 所以我们需要实参page的值
'limit': 20
}
data = urllib.parse.urlencode(data)
url = first_url + data
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
requerst = urllib.request.Request(url=url, headers=headers)
return requerst
def reqopne_get(requerst):
content = urllib.request.urlopen(requerst) # 模拟浏览器像服务器发送请求
contents = content.read().decode('utf-8')
return contents # 返回contents的值
def plase_get(page, contents):
filename = 'douban.' + str(page) + 'json'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(contents)
print('保存完成')
if __name__ == '__main__':
utf_name = int(input('请输入开始页码'))
last_name = int(input('请输入结束页码'))
for page in range(utf_name, last_name + 1): # 左闭又开想要获取10页数据 10+1 11获取第10页数据
# 请求对象定制
requerst = requert_get(page)
# 获取响应的数据
contents = reqopne_get(requerst)
# 下载数据
plase_get(page, contents)
```
你在22行下打印一下,看看有没有拿到数据,print输出一下contents
headers里面多插入几个请求头试一下,比如referer
网站更新反爬了,代码失效就拿不到数据了