在使用lxml读取xml文件时 xpath('//*' ) 可以读取到所有的标签,但是我输入中文xpath('//记账凭证类型') 文件里面有这个标签的,返回结果却为空
在使用lxml读取xml文件时 xpath('//*' ) 可以读取到所有的标签,但是我输入中文xpath('//记账凭证类型') 文件里面有这个标签的,返回结果却为空
from lxml import etree
path=r'C:\Users\1\Desktop\补采数据20220613\1_国标2010格式文件__禄劝彝族苗族自治县第一中学初中食堂账\国标核算总账类_禄劝彝族苗族自治县第一中学初中食堂账.xml'
html = etree.parse(path)
root=html.getroot()
print(root.tag)
print(root.items())
for a in root:
pass
# print(a.tag)
# print(a.items())
# print(a.text)
# for b in a:
# print(b.tag)
# print(b.items())
# print(b.text)
# print(len(a))
xc=html.xpath('//记账凭证类型')
print(xc)
for xc in xc:
print(xc.tag)
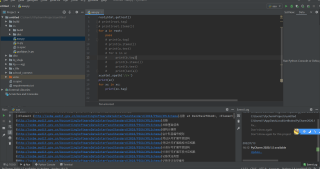
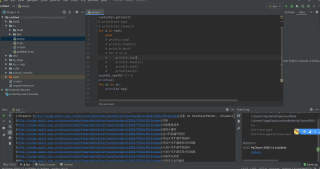
你的文本呢,截图瞅瞅
xpath('//总账/记账凭证类型')
可能你把xpath用法理解错了
改为英文的xml试试,可能是不支持标签中文