python语言解析URL
输入规格
每行一个待解析的URL字符串,整行读入,处理到EOF为止。
输出规格
对每个URL,以JSON格式输出解析结果:
{
"scheme": "",
"authority": {
"user": "",
"host": "",
"port": 0,
},
"path": "",
"query": {},
"fragment": ""
}
每级缩进为2个空格。
如某个成分不存在,对应的值输出null。如成分存在但为空,输出空串。
端口特殊处理:按整数输出,不加引号。如未指定则输出默认端口。
authority为空时值设为null。
query
如不存在(没有?部分)输出null
如存在,根据&拆分成多个键值对,再根据=取出键和值。
如存在但没有值,输出{}
fragment
如不存在(没有#部分)输出null
如存在,值为#后的部分(可能为空串)。
样例输入
http://admin@127.0.0.1:9999/manual/search.php?target=print&limit=10#view=fit&row=5
https://gitee.com/codearhat/cpplab.git?#
ftp://guest@127.0.0.1:2121/pub/rfc3986.txt
样例输出
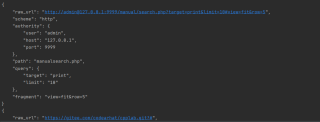
{
"raw_url": "http://admin@127.0.0.1:9999/manual/search.php?target=print&limit=10#view=fit&row=5",
"scheme": "http",
"authority": {
"user": "admin",
"host": "127.0.0.1",
"port": 9999
},
"path": "/manual/search.php",
"query": {
"target": "print",
"limit": "10"
},
"fragment": "view=fit&row=5"
}
{
"raw_url": "https://gitee.com/codearhat/cpplab.git?#%22,
"scheme": "https",
"authority": {
"user": null,
"host": "gitee.com",
"port": 443
},
"path": "/codearhat/cpplab.git",
"query": {},
"fragment": ""
}
{
"raw_url": "ftp://guest@127.0.0.1:2121/pub/rfc3986.txt",
"scheme": "ftp",
"authority": {
"user": "guest",
"host": "127.0.0.1",
"port": 2121
},
"path": "/pub/rfc3986.txt",
"query": null,
"fragment": null
}
样例解释
第1组:成分齐全。
第2组:有认证部分,但没用户名,补充默认端口。query和fragment部分存在,内容为空,输出空对象和空串。
第3组:没有query或fragment部分。
import json
def my_split(string: str, op: str, index: int) -> str:
"""
:param string:
:param op:
:param index:
:return:
"""
if op in string:
return string.split(op)[index]
return "null"
def operate(link: str) -> str:
"""
:param link:
:return:
"""
raw_url = link
scheme = link.split(":")[0]
data = "".join(link[len(scheme):])[3:].split('/')
data[1] = data[1] + data[2]
data.pop(-1)
user = my_split(data[0], "@", 0)
host = ""
if user != "null":
host += my_split("".join(data[0].split('@')[1:]), ":", 0)
else:
host += data[0]
port = my_split(data[0], ":", -1)
if port == "null":
port = 443
else:
port = int(port)
path = ""
fragment = ""
query = {}
if "?" in data[1]:
path = data[1].split('?')[0]
fragment = my_split(data[1], "#", -1)
keys = "".join(data[1].split('?')[1:]).split("#")[0].split("&")
if keys[0] != "":
for i in keys:
query[i.split('=')[0]] = i.split('=')[1]
else:
path = data[1]
fragment = "null"
res = {"raw_url": raw_url, 'scheme': scheme, "authority": {"user": user, "host": host, "port": port}, "path": path,
"query": query, "fragment": fragment}
res = json.dumps(res, indent=4, separators=(',', ': '))
return res
if __name__ == '__main__':
url_arr = ["http://admin@127.0.0.1:9999/manual/search.php?target=print&limit=10#view=fit&row=5",
"https://gitee.com/codearhat/cpplab.git?#",
"ftp://guest@127.0.0.1:2121/pub/rfc3986.txt"]
for url in url_arr:
result = operate(url)
print(result)
python里面的你的null我用“null”,需要空值的话你可以自己再转换一下,其他人的答案都可以,转有空格的字符串你可以用json库操作
有自带的库来解析,格式有一些差异,可以自己转换,比如query,自带的解析出来是字符串,可以拆分成字典。
参考:https://docs.python.org/zh-cn/3/library/urllib.parse.html
from urllib.parse import urlparse
def f(url):
tmp=urlparse(url)
re_json={}
re_json['raw_url']=url
re_json['scheme']=tmp.scheme
authority={}
user=tmp.username
authority['user']=user
authority['host']=tmp.hostname
authority['port']=tmp.port
if(tmp.port==None):
authority['port']=443 #port默认值
re_json['authority']=authority
re_json['path']=tmp.path
if(tmp.query!=''):
que=tmp.query
query={}
kvs=que.split('&')
print(kvs)
for i in kvs:
kv=i.split('=')
query[kv[0]]=kv[1]
else:
if(url.count('?')):
query={}
else:
query=None
re_json['query']=query
re_json['fargment']=tmp.fragment
if(url.find('#')==-1):
re_json['fargment']=None
return re_json
urls=['http://admin@127.0.0.1:9999/manual/search.php?target=print&limit=10#view=fit&row=5',
'https://gitee.com/codearhat/cpplab.git?#',
'ftp://guest@127.0.0.1:2121/pub/rfc3986.txt',]
for url in urls:
print(f(url))