分布式训练DistributedDataParallel 中dist.barrier()的使用
问题遇到的现象和发生背景
在使用DistributedDataParallel进行分布式训练的时候发现,dist.barrier()函数并不起作用
问题相关代码,请勿粘贴截图
import os
import torch
import argparse
import torch.nn as nn
import torch.multiprocessing as mp
from PIL import Image
from torch.utils.data import Dataset
from torch import distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import Adam
from torch.optim.lr_scheduler import StepLR
class ddp_dataset(Dataset):
def __init__(self, image_path):
self.path = image_path
self.image = os.listdir(self.path)
super(ddp_dataset, self).__init__()
def __len__(self):
return len(self.image)
def __getitem__(self, item):
image_name = self.image[item]
image = Image.open(os.path.join(self.path, image_name)).convert('RGB')
image = transforms.Resize((256,256))(image)
image = transforms.ToTensor()(image)
label = torch.tensor(0).long()
return image,label
class X_net(nn.Module):
def __init__(self, inchannels, num_classes):
super(X_net, self).__init__()
self.conv1 = nn.Conv2d(inchannels,64, 5, 2, 0)
self.conv2 = nn.Conv2d(64, 128, 5, 2, 0)
self.conv3 = nn.Conv2d(128, 512, 5, 5, 0)
self.avg = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(512, num_classes)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.avg(x)
x = x[:,:, -1].squeeze(-1)
x = self.fc1(x)
return x
def set_args():
parser = argparse.ArgumentParser()
parser.add_argument('--rank', type = int, default = 0)
parser.add_argument('--image_path', type=str, default='/home/wangyn/xjm/ALBEF_mv/img_data/train2014')
parser.add_argument('--world_size', type=int, default=2)
parser.add_argument('--distributed_addr', type=str, default='localhost')
parser.add_argument('--distributed_port', type=str, default='12355')
args = parser.parse_args()
return args
def _init_distributed(args):
os.environ['MASTER_ADDR'] = args.distributed_addr
os.environ['MASTER_PORT'] = args.distributed_port
dist.init_process_group('nccl', rank = args.rank, world_size= args.world_size)
def main(rank, args):
print(f'this is rank{rank}')
args.rank = rank
_init_distributed(args)
dataset = ddp_dataset(args.image_path)
a,d = dataset[1]
sampler = DistributedSampler(
dataset = dataset,
rank = args.rank,
num_replicas=args.world_size,
shuffle= True
)
dataloader = DataLoader(
dataset = dataset,
batch_size=8,
num_workers=0,
sampler = sampler,
pin_memory=False
)
model = X_net(3,5).to(args.rank)
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model_ddp = DDP(model, device_ids=[args.rank],output_device = args.rank)
optimizer = Adam(model_ddp.parameters(), lr = 0.001)
scheduler = StepLR(optimizer, step_size=1, gamma=0.1)
Trainer(args, model_ddp, dataloader, optimizer, scheduler,sampler)
def Trainer(args, model, dataloader, optimizer, scheduler, sampler):
print(f'rank{args.rank} start training')
model.train()
critioner = nn.CrossEntropyLoss()
c = 0
for epoch in range(200):
sampler.set_epoch(epoch)
for input, label in dataloader:
print(f'rank{args.rank}新一轮训练')
input, label = input.to(args.rank), label.to(args.rank)
out = model(input)
loss = critioner(out, label)
optimizer.zero_grad()
loss.backward()
print('this is optimizer')
optimizer.step()
print(f'rank{args.rank} loss is {loss}')
# scheduler.step()
if args.rank == 0:
print(f'start valid')
model.eval()
out = model(input)
model.train()
print('over valid')
dist.barrier()
else:
dist.barrier()
c += 1
print(f'rank{args.rank} :{c}')
# else:
# dist.barrier()
print(f'rank{args.rank} after barrier')
# for i in range(10):
# print(f'rank{args.rank}:{i}')
# dist.barrier()
if __name__ == '__main__':
args = set_args()
mp.spawn(main, args = (args,), nprocs=args.world_size, join=True)
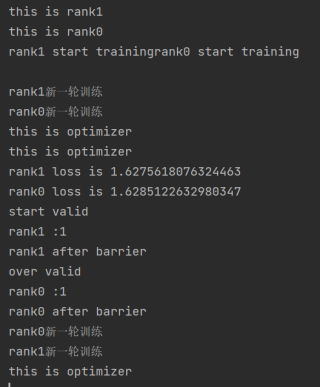
运行结果及报错内容
结果卡死在optimizer.step()
我的解答思路和尝试过的方法
本来我是希望在指定训练epoch次数后对模型进行验证,但是我发现在验证之后,无法恢复训练,网上说dist.barrier()是用来同步进程的,按理来说我这么写没问题呀!
我想要达到的结果
我想知道为什么验证以后无法正常训练